Dự án AI Agentic: Xây dựng hệ thống đa tác tử với LangGraph

Đây là một dự án toàn diện về việc xây dựng hệ thống hỗ trợ bảo hiểm đa tác tử sử dụng Agentic AI [LangGraph và OpenAI API]. [Bao gồm mã nguồn].
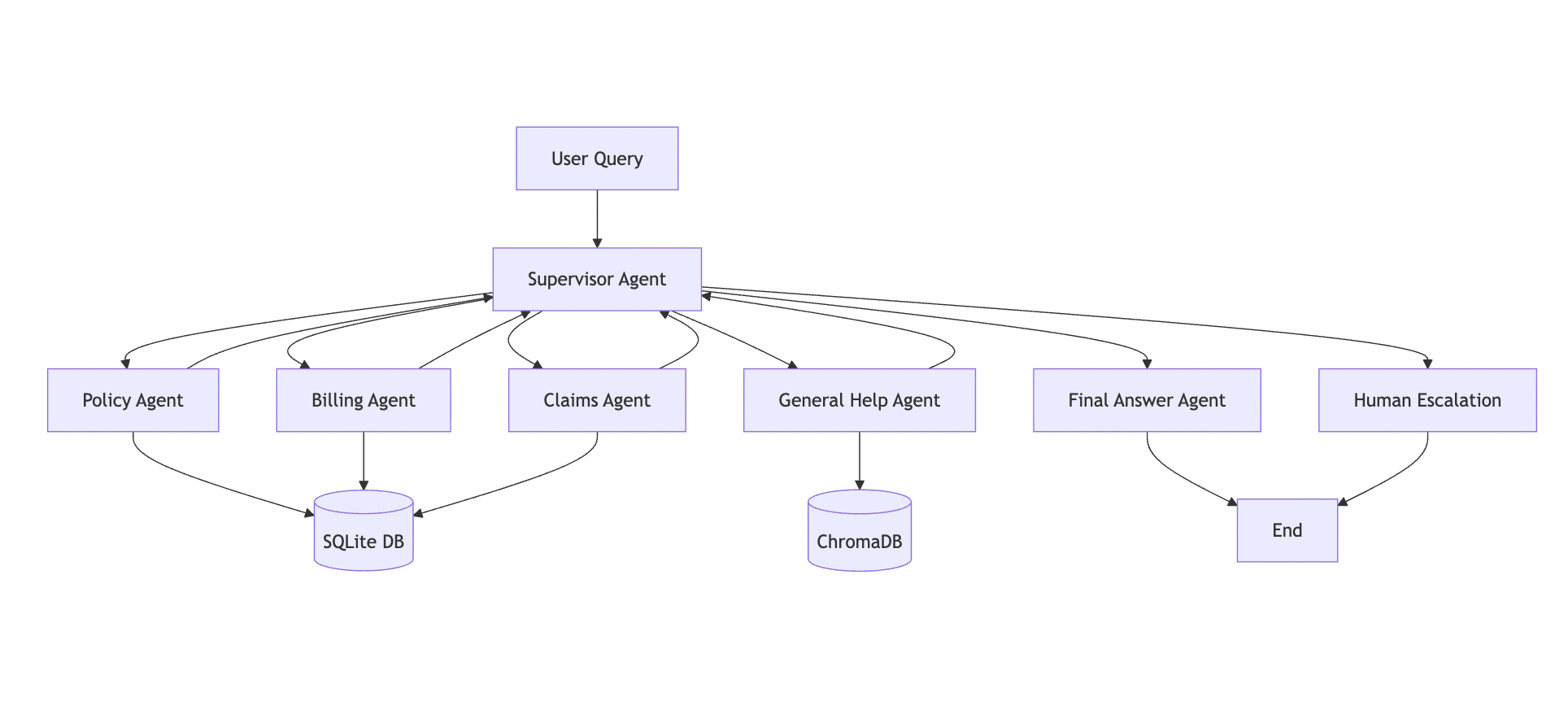 Kiến trúc hệ thống đa tác tử [Ảnh của tác giả]
Kiến trúc hệ thống đa tác tử [Ảnh của tác giả]
Phép loại suy
Gần đây, tôi gọi đến số chăm sóc khách hàng của công ty bảo hiểm để biết số tiền phí bảo hiểm cho hợp đồng của mình. Họ nói: "Để tôi chuyển cuộc gọi của bạn đến phòng thanh toán."
Sau đó, một nhân viên từ phòng thanh toán đã giải quyết thắc mắc của tôi.
Vài ngày sau, tôi gọi lại và hỏi về tình trạng yêu cầu bồi thường của mình. Họ nói: "Để tôi chuyển cuộc gọi của bạn đến phòng khiếu nại."
Sau đó, một nhân viên từ phòng khiếu nại đã giải quyết thắc mắc của tôi.
Về cơ bản, đối với mỗi loại truy vấn, họ có các nhân viên chuyên gia chuyên giải quyết những vấn đề cụ thể đó.
Đó chính xác là cách một hệ thống đa tác tử hoạt động — các tác tử khác nhau được thiết kế cho các loại nhiệm vụ khác nhau, và một hệ thống trung tâm sẽ định tuyến truy vấn đến đúng chuyên gia.
Tóm lại: Mỗi tác tử làm những gì nó giỏi nhất, và cùng nhau, chúng mang lại một giải pháp thông minh hơn, nhanh hơn.
 Hệ thống hỗ trợ bảo hiểm (Ảnh của tác giả: Tạo bởi Gemini)
Hệ thống hỗ trợ bảo hiểm (Ảnh của tác giả: Tạo bởi Gemini)
Tuyên bố vấn đề:
Hỗ trợ khách hàng truyền thống trong ngành bảo hiểm thường chậm, rời rạc và không hiệu quả. Khách hàng thường phải đối mặt với:
- Thời gian chờ đợi lâu và nhiều lần chuyển giao
- Yêu cầu dữ liệu lặp đi lặp lại (“Bạn có thể xác nhận lại số hợp đồng của mình không?”)
- Phản hồi chatbot chung chung, thiếu ngữ cảnh hoặc độ chính xác
- Khó khăn trong việc truy cập thông tin cá nhân hóa về hợp đồng, thanh toán hoặc khiếu nại trong thời gian thực
Ngay cả với tự động hóa, hầu hết các hệ thống đều dựa vào chatbot đơn mục đích không thể xử lý bản chất phức tạp, đa lĩnh vực của các yêu cầu bảo hiểm. Điều này dẫn đến khách hàng thất vọng, đội ngũ hỗ trợ quá tải, và bỏ lỡ cơ hội nâng cao hiệu quả.
Hướng tiếp cận giải pháp:
Chúng tôi đã xây dựng một hệ thống hỗ trợ bảo hiểm đa tác tử do AI cung cấp, mô phỏng một đội ngũ chuyên gia con người bằng cách sử dụng điều phối LangGraph và RAG (Retrieval-Augmented Generation).
Một Tác tử Giám sát (Supervisor Agent) phân tích ý định của người dùng và định tuyến mỗi truy vấn đến các tác tử chuyên biệt về hợp đồng, thanh toán, khiếu nại, hoặc trợ giúp chung. Các tác tử này truy cập dữ liệu thực tế thông qua SQLite và ChromaDB, đảm bảo các phản hồi có cơ sở thực tế và nhận biết ngữ cảnh.
Bằng cách quản lý trạng thái cuộc trò chuyện, logic định tuyến và truy xuất dữ liệu một cách thông minh, hệ thống mang lại hỗ trợ khách hàng chính xác, cá nhân hóa và có khả năng mở rộng — đồng thời chuyển các trường hợp phức tạp cho con người một cách liền mạch khi cần thiết.
Trong bài viết này, tôi sẽ hướng dẫn bạn xây dựng một hệ thống hỗ trợ bảo hiểm đa tác tử tinh vi, có khả năng định tuyến thông minh các truy vấn của khách hàng đến các tác tử chuyên biệt, truy xuất thông tin từ cơ sở dữ liệu và tận dụng RAG (Retrieval-Augmented Generation) để có các phản hồi chính xác.
Tham khảo Repo Github này để xem mã nguồn hoàn chỉnh.
Những gì chúng ta sẽ xây dựng
Hệ thống của chúng tôi bao gồm:
- Tác tử Giám sát (Supervisor Agent) — Người điều phối phân tích ý định của người dùng và định tuyến đến các chuyên gia phù hợp.
- Tác tử Hợp đồng (Policy Agent) — Xử lý chi tiết hợp đồng, phạm vi bảo hiểm và các thông tin cụ thể về bảo hiểm ô tô.
- Tác tử Thanh toán (Billing Agent) — Quản lý các yêu cầu về thanh toán, lịch sử thanh toán và thông tin hóa đơn.
- Tác tử Khiếu nại (Claims Agent) — Xử lý tình trạng khiếu nại và hỗ trợ nộp hồ sơ.
- Tác tử Trợ giúp chung (General Help Agent) — Trả lời các câu hỏi thường gặp (FAQ) bằng RAG với cơ sở dữ liệu vector.
- Tác tử Chuyển giao cho con người (Human Escalation Agent) — Chuyển giao các trường hợp phức tạp cho nhân viên hỗ trợ một cách lịch sự.
Hệ thống sử dụng LangGraph để điều phối quy trình làm việc, ChromaDB để tìm kiếm ngữ nghĩa, SQLite cho dữ liệu có cấu trúc, và OpenAI GPT để hiểu ngôn ngữ tự nhiên.
Kiến trúc hệ thống
Quy trình làm việc hoạt động như một máy trạng thái (state machine), trong đó:
- Mỗi tác tử là một nút (node) trong đồ thị.
- Tác tử giám sát hoạt động như bộ định tuyến trung tâm, đưa ra các quyết định thông minh dựa trên cuộc trò chuyện.
- Các tác tử chuyên gia (Hợp đồng, Thanh toán, v.v.) thực hiện nhiệm vụ của mình và trả lại quyền kiểm soát cho tác tử giám sát.
- Cuộc trò chuyện kết thúc khi truy vấn được giải quyết hoặc được chuyển giao thành công cho con người.
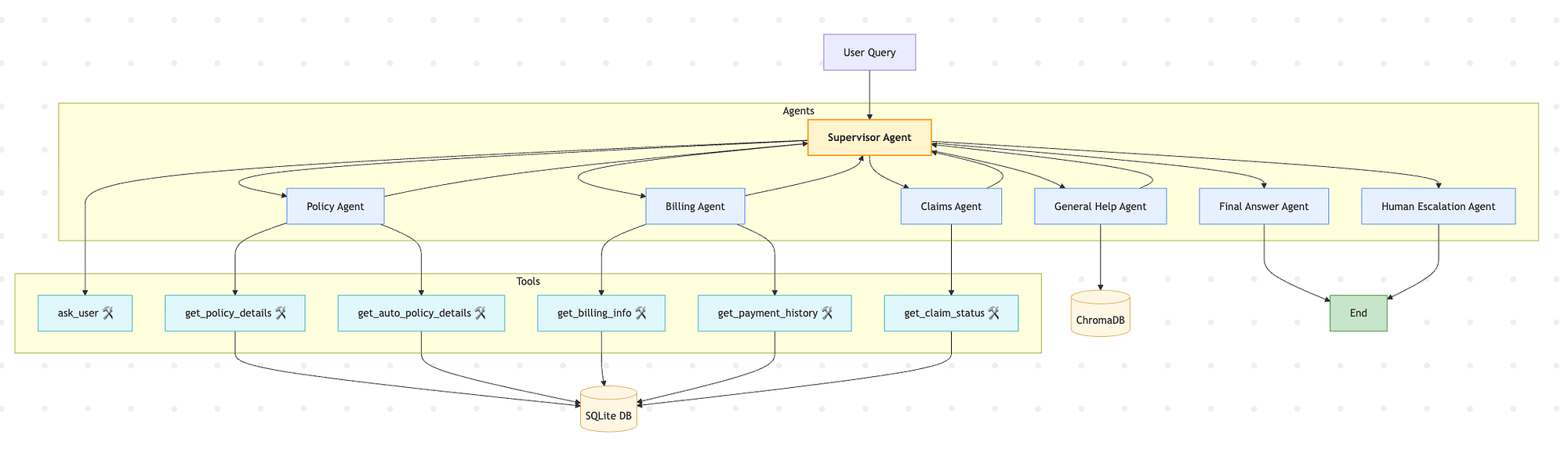 Hệ thống hỗ trợ bảo hiểm: Kiến trúc đa tác tử (Ảnh của tác giả)
Hệ thống hỗ trợ bảo hiểm: Kiến trúc đa tác tử (Ảnh của tác giả)
Ngăn xếp công nghệ
- Điều phối:
LangGraph - LLM: OpenAI
gpt-5-mini - Cơ sở dữ liệu Vector:
ChromaDB - Cơ sở dữ liệu Quan hệ:
SQLite - Xử lý dữ liệu:
Pandas,NumPy - Ghi log: Python
logging - Giám sát Prompt:
**Arize Phoenix**
Hãy bắt đầu nào:
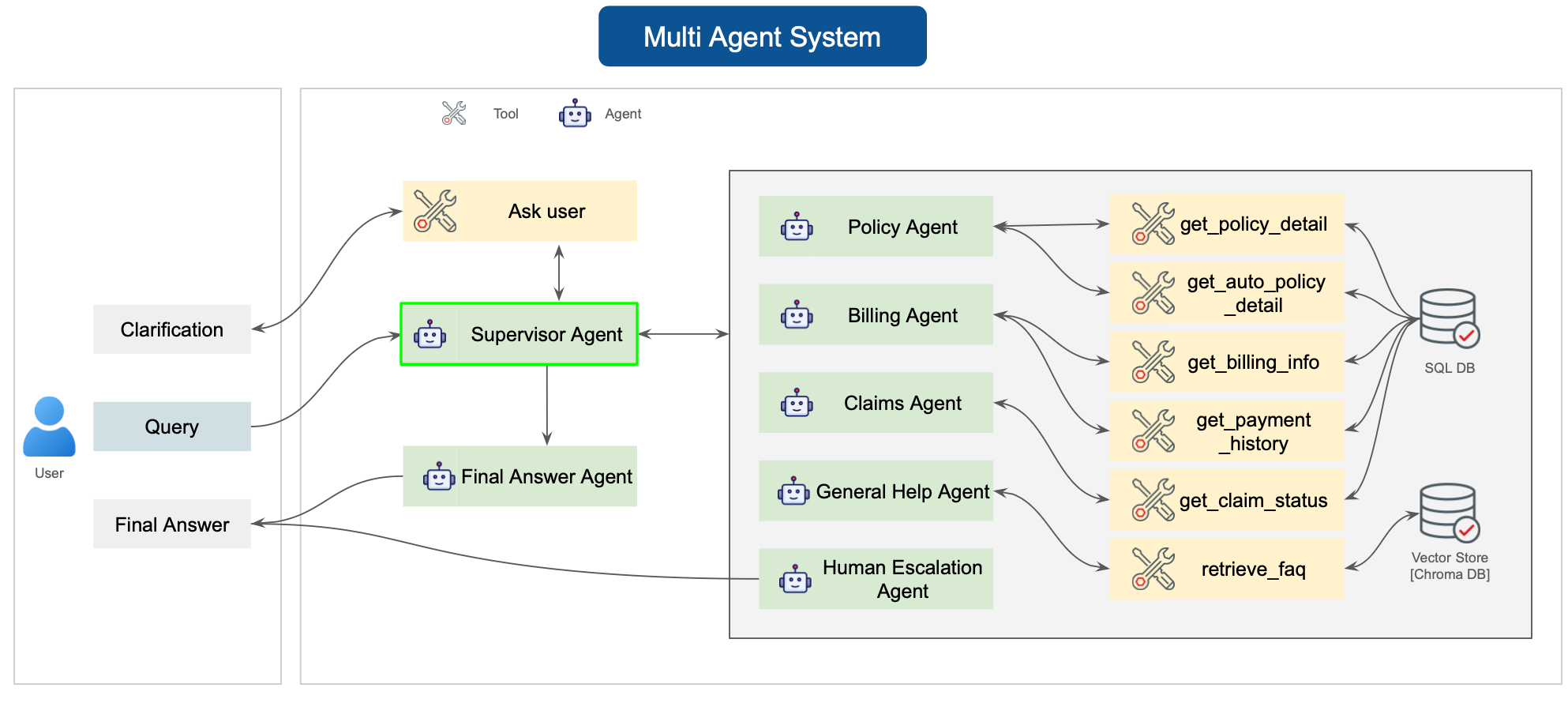 Hệ thống đa tác tử (Hệ thống hỗ trợ bảo hiểm): [Ảnh của tác giả]
Hệ thống đa tác tử (Hệ thống hỗ trợ bảo hiểm): [Ảnh của tác giả]
Nhập các thư viện cần thiết:
Chúng tôi nhập các thư viện cần thiết và tải khóa API của OpenAI và phoenix_endpoint.
#importing the required libraries
import pandas as pd
import numpy as np
import json
import re
from typing import List, Dict, Any, Tuple
from openai import OpenAI
import time
from dotenv import load_dotenv
import openai
import os
from datasets import load_dataset
import chromadb
from datetime import datetime, timedelta
import random
import sqlite3
from opentelemetry.trace.status import Status, StatusCode
from opentelemetry.trace import get_current_span
from phoenix.otel import register
# ✅ Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPEN_AI_KEY")
phoenix_endpoint = os.getenv("PHOENIX_COLLECTOR_ENDPOINT")
Hạ tầng dữ liệu
A. Dữ liệu tổng hợp trên SQLite DB
Bây giờ chúng tôi tạo các bộ dữ liệu tổng hợp, có liên quan với nhau cho một công ty bảo hiểm giả lập — bao gồm khách hàng, hợp đồng, thanh toán, các khoản thanh toán và khiếu nại — sử dụng pandas, numpy, và các mô-đun datetime và random của Python.
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import random
def generate_sample_data(random_state=42):
"""Generate enriched sample data for all tables with 50 first/last names"""
random.seed(random_state)
np.random.seed(random_state)
# Define 50 first and last names
first_names = [
"John", "Jane", "Robert", "Maria", "David", "Lisa", "Michael", "Sarah", "James", "Emily",
"William", "Emma", "Joseph", "Olivia", "Charles", "Ava", "Thomas", "Isabella", "Daniel", "Mia",
"Matthew", "Sophia", "Anthony", "Charlotte", "Christopher", "Amelia", "Andrew", "Harper",
"Joshua", "Evelyn", "Ryan", "Abigail", "Brandon", "Ella", "Justin", "Scarlett", "Tyler", "Grace",
"Alexander", "Chloe", "Kevin", "Victoria", "Jason", "Lily", "Brian", "Hannah", "Eric", "Aria",
"Kyle", "Zoey"
]
last_names = [
"Smith", "Johnson", "Williams", "Brown", "Jones", "Garcia", "Miller", "Davis", "Rodriguez", "Martinez",
"Hernandez", "Lopez", "Gonzalez", "Wilson", "Anderson", "Thomas", "Taylor", "Moore", "Jackson", "Martin",
"Lee", "Perez", "Thompson", "White", "Harris", "Sanchez", "Clark", "Ramirez", "Lewis", "Robinson",
"Walker", "Young", "Allen", "King", "Wright", "Scott", "Torres", "Nguyen", "Hill", "Flores",
"Green", "Adams", "Nelson", "Baker", "Hall", "Rivera", "Campbell", "Mitchell", "Carter", "Roberts"
]
# Generate customers (1000 random name combinations)
customers = pd.DataFrame({
'customer_id': [f'CUST{str(i).zfill(5)}' for i in range(1, 1001)],
'first_name': [random.choice(first_names) for _ in range(1000)],
'last_name': [random.choice(last_names) for _ in range(1000)],
'email': [f'user{i}@example.com' for i in range(1, 1001)],
'phone': [f'555-{str(random.randint(100,999)).zfill(3)}-{str(random.randint(1000,9999)).zfill(4)}' for _ in range(1000)],
'date_of_birth': [datetime(1980, 1, 1) + timedelta(days=random.randint(0, 10000)) for _ in range(1000)],
'state': [random.choice(['CA', 'NY', 'TX', 'FL', 'IL', 'PA', 'OH', 'GA']) for _ in range(1000)]
})
# Policies
policies = pd.DataFrame({
'policy_number': [f'POL{str(i).zfill(6)}' for i in range(1, 1501)],
'customer_id': [f'CUST{str(random.randint(1, 1000)).zfill(5)}' for _ in range(1500)],
'policy_type': [random.choice(['auto', 'home', 'life']) for _ in range(1500)],
'start_date': [datetime(2023, 1, 1) + timedelta(days=random.randint(0, 365)) for _ in range(1500)],
'premium_amount': [round(random.uniform(50, 500), 2) for _ in range(1500)],
'billing_frequency': [random.choice(['monthly', 'quarterly', 'annual']) for _ in range(1500)],
'status': [random.choice(['active', 'active', 'active', 'cancelled']) for _ in range(1500)]
})
# Auto Policy Details (subset)
auto_policies = policies[policies['policy_type'] == 'auto'].copy()
auto_policy_details = pd.DataFrame({
'policy_number': auto_policies['policy_number'],
'vehicle_vin': [f'VIN{random.randint(10000000000000000, 99999999999999999)}' for _ in range(len(auto_policies))],
'vehicle_make': [random.choice(['Toyota', 'Honda', 'Ford', 'Chevrolet', 'Nissan']) for _ in range(len(auto_policies))],
'vehicle_model': [random.choice(['Camry', 'Civic', 'F-150', 'Malibu', 'Altima']) for _ in range(len(auto_policies))],
'vehicle_year': [random.randint(2015, 2023) for _ in range(len(auto_policies))],
'liability_limit': [random.choice([50000, 100000, 300000]) for _ in range(len(auto_policies))],
'collision_deductible': [random.choice([250, 500, 1000]) for _ in range(len(auto_policies))],
'comprehensive_deductible': [random.choice([250, 500, 1000]) for _ in range(len(auto_policies))],
'uninsured_motorist': [random.choice([0, 1]) for _ in range(len(auto_policies))],
'rental_car_coverage': [random.choice([0, 1]) for _ in range(len(auto_policies))]
})
# Billing
billing = pd.DataFrame({
'bill_id': [f'BILL{str(i).zfill(6)}' for i in range(1, 5001)],
'policy_number': [random.choice(policies['policy_number']) for _ in range(5000)],
'billing_date': [datetime(2024, 1, 1) + timedelta(days=random.randint(0, 90)) for _ in range(5000)],
'due_date': [datetime(2024, 1, 15) + timedelta(days=random.randint(0, 90)) for _ in range(5000)],
'amount_due': [round(random.uniform(100, 1000), 2) for _ in range(5000)],
'status': [random.choice(['paid', 'pending', 'overdue']) for _ in range(5000)]
})
# Payments
payments = pd.DataFrame({
'payment_id': [f'PAY{str(i).zfill(6)}' for i in range(1, 4001)],
'bill_id': [random.choice(billing['bill_id']) for _ in range(4000)],
'payment_date': [datetime(2024, 1, 1) + timedelta(days=random.randint(0, 90)) for _ in range(4000)],
'amount': [round(random.uniform(50, 500), 2) for _ in range(4000)],
'payment_method': [random.choice(['credit_card', 'debit_card', 'bank_transfer']) for _ in range(4000)],
'transaction_id': [f'TXN{random.randint(100000,999999)}' for _ in range(4000)],
'status': [random.choice(['completed', 'pending', 'failed']) for _ in range(4000)]
})
# Claims
claims = pd.DataFrame({
'claim_id': [f'CLM{str(i).zfill(6)}' for i in range(1, 301)],
'policy_number': [random.choice(policies['policy_number']) for _ in range(300)],
'claim_date': [datetime(2024, 1, 1) + timedelta(days=random.randint(0, 90)) for _ in range(300)],
'incident_type': [random.choice(['collision', 'theft', 'property_damage', 'medical', 'liability']) for _ in range(300)],
'estimated_loss': [round(random.uniform(500, 20000), 2) for _ in range(300)],
'status': [random.choice(['submitted', 'under_review', 'approved', 'paid', 'denied']) for _ in range(300)]
})
return {
'customers': customers,
'policies': policies,
'auto_policy_details': auto_policy_details,
'billing': billing,
'payments': payments,
'claims': claims,
}
sample_data = generate_sample_data()
Do đó, chúng tôi tạo ra tổng cộng 6 bảng như sau:
A1: Bảng Khách hàng (Customers)
Chứa thông tin cá nhân và liên hệ của tất cả khách hàng bảo hiểm.
print("Customers Data Shape:", sample_data["customers"].shape)
sample_data["customers"].head()

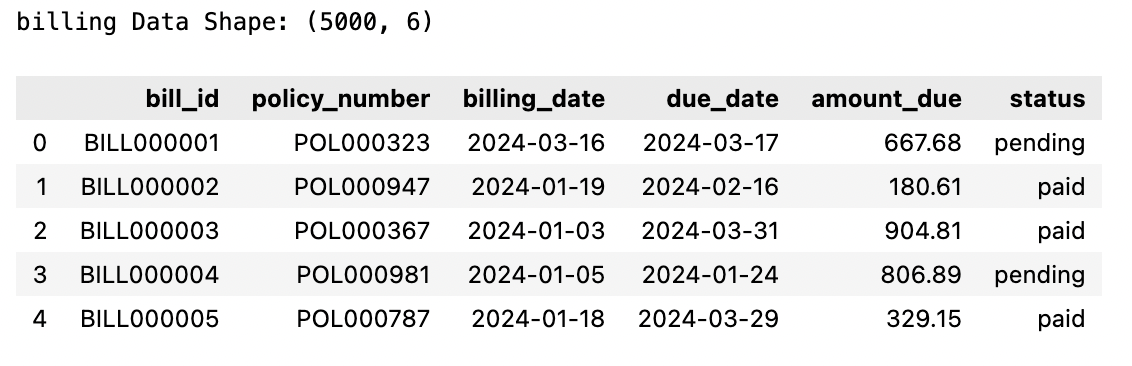
A2: Bảng Thanh toán (Billing)
Theo dõi tất cả các hóa đơn được phát hành cho các hợp đồng bảo hiểm, bao gồm ngày đến hạn và trạng thái thanh toán.
print("billing Data Shape:", sample_data["billing"].shape)
sample_data["billing"].head()
A3: Dữ liệu Thanh toán (Payment)
Ghi lại các giao dịch thanh toán cho hóa đơn, bao gồm phương thức và trạng thái giao dịch.
print("payments Data Shape:", sample_data["payments"].shape)
sample_data["payments"].head()
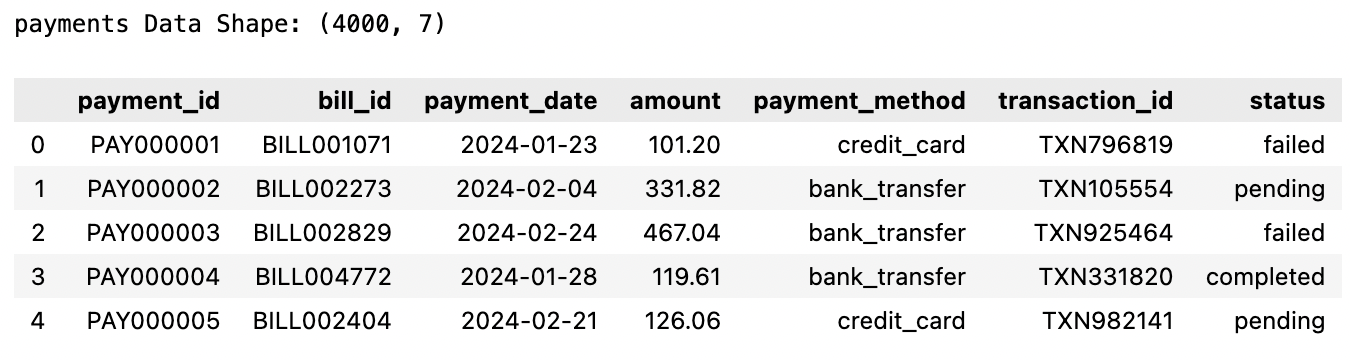
A4: Dữ liệu Khiếu nại (Claims)
Ghi lại các yêu cầu bồi thường bảo hiểm được nộp theo hợp đồng với chi tiết về sự cố và trạng thái yêu cầu.
print("claims Data Shape:", sample_data["claims"].shape)
sample_data["claims"].head()
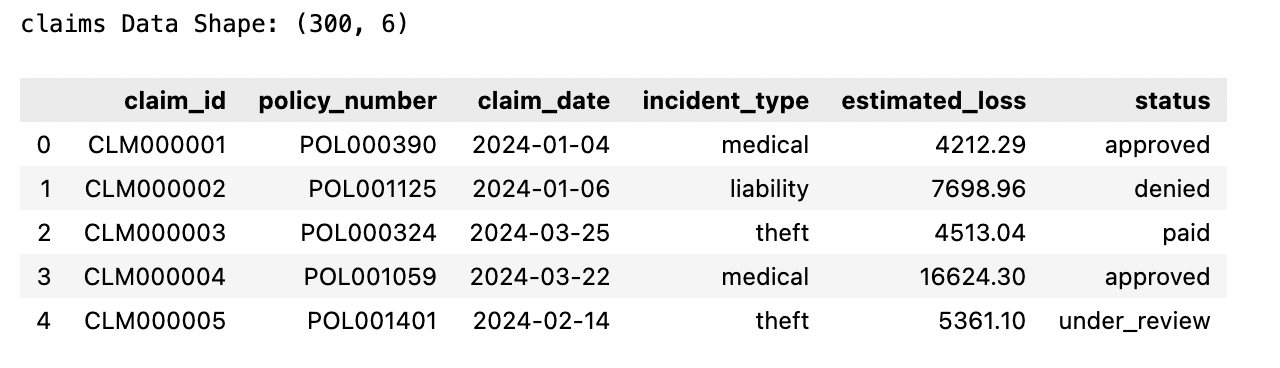
A5: Dữ liệu Hợp đồng (Policy)
Lưu trữ thông tin về hợp đồng bảo hiểm của mỗi khách hàng, bao gồm loại, ngày bắt đầu và trạng thái.
print("policies Data Shape:", sample_data["policies"].shape)
sample_data["policies"].head()
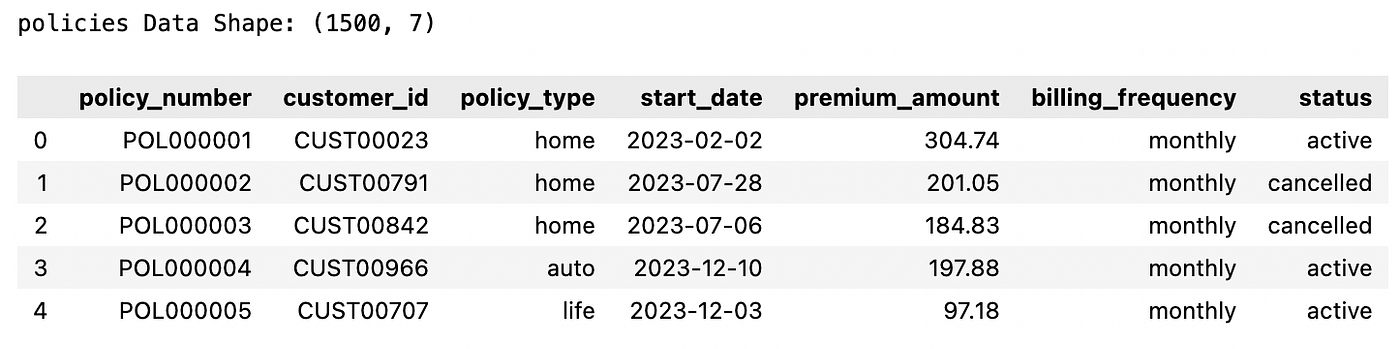
A6: Dữ liệu Hợp đồng ô tô (Auto Policy)
Lưu trữ chi tiết cụ thể về xe cho các hợp đồng bảo hiểm ô tô.
print("auto policies Data Shape:", sample_data["auto_policy_details"].shape)
sample_data["auto_policy_details"].head()
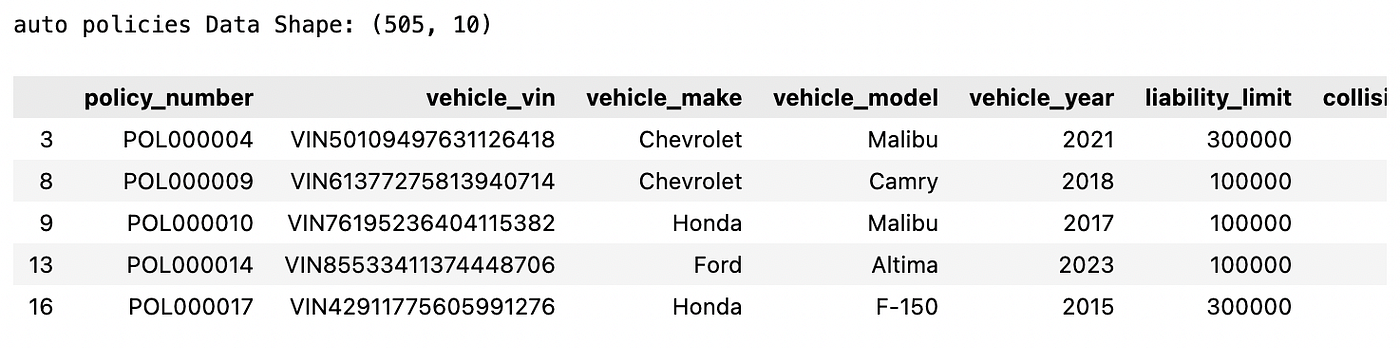
A7: Tải dữ liệu lên SQLite DB:
Đầu tiên, chúng tôi tạo cơ sở dữ liệu SQLite3 insurance_support.db và định nghĩa hàm để tạo các bảng.
import sqlite3
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import random
import json
def connect_db(db_path='insurance_support.db'):
"""Connect to SQLite database"""
return sqlite3.connect(db_path)
def drop_and_create_tables(conn):
"""Drop existing tables and recreate the schema"""
cursor = conn.cursor()
# Drop tables if exist
cursor.executescript("""
DROP TABLE IF EXISTS claims;
DROP TABLE IF EXISTS payments;
DROP TABLE IF EXISTS billing;
DROP TABLE IF EXISTS auto_policy_details;
DROP TABLE IF EXISTS policies;
DROP TABLE IF EXISTS customers;
""")
# Create tables
cursor.executescript("""
CREATE TABLE customers (
customer_id VARCHAR(20) PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
phone VARCHAR(20),
date_of_birth DATE,
state VARCHAR(20)
);
CREATE TABLE policies (
policy_number VARCHAR(20) PRIMARY KEY,
customer_id VARCHAR(20),
policy_type VARCHAR(50),
start_date DATE,
premium_amount DECIMAL(10,2),
billing_frequency VARCHAR(20),
status VARCHAR(20),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
CREATE TABLE auto_policy_details (
policy_number VARCHAR(20) PRIMARY KEY,
vehicle_vin VARCHAR(50),
vehicle_make VARCHAR(50),
vehicle_model VARCHAR(50),
vehicle_year INTEGER,
liability_limit DECIMAL(10,2),
collision_deductible DECIMAL(10,2),
comprehensive_deductible DECIMAL(10,2),
uninsured_motorist BOOLEAN,
rental_car_coverage BOOLEAN,
FOREIGN KEY (policy_number) REFERENCES policies(policy_number)
);
CREATE TABLE billing (
bill_id VARCHAR(20) PRIMARY KEY,
policy_number VARCHAR(20),
billing_date DATE,
due_date DATE,
amount_due DECIMAL(10,2),
status VARCHAR(20),
FOREIGN KEY (policy_number) REFERENCES policies(policy_number)
);
CREATE TABLE payments (
payment_id VARCHAR(20) PRIMARY KEY,
bill_id VARCHAR(20),
payment_date DATE,
amount DECIMAL(10,2),
payment_method VARCHAR(50),
transaction_id VARCHAR(100),
status VARCHAR(20),
FOREIGN KEY (bill_id) REFERENCES billing(bill_id)
);
CREATE TABLE claims (
claim_id VARCHAR(20) PRIMARY KEY,
policy_number VARCHAR(20),
claim_date DATE,
incident_type VARCHAR(100),
estimated_loss DECIMAL(10,2),
status VARCHAR(20),
FOREIGN KEY (policy_number) REFERENCES policies(policy_number)
);
""")
conn.commit()
def insert_data(conn, data):
"""Insert all DataFrames into SQLite"""
for table, df in data.items():
df.to_sql(table, conn, if_exists='append', index=False)
conn.commit()
def setup_insurance_database(data):
"""Main function to create and populate the insurance database"""
conn = connect_db()
drop_and_create_tables(conn)
insert_data(conn, data)
conn.close()
print("✅ Database created successfully with enriched synthetic data!")
setup_insurance_database(sample_data)
✅ Database created successfully with enriched synthetic data!
Kiểm tra kết nối SQL:
# test the SQL connection
conn = connect_db()
query = "SELECT * FROM customers LIMIT 5;"
df_sql = pd.read_sql_query(query, conn)
conn.close()
df_sql
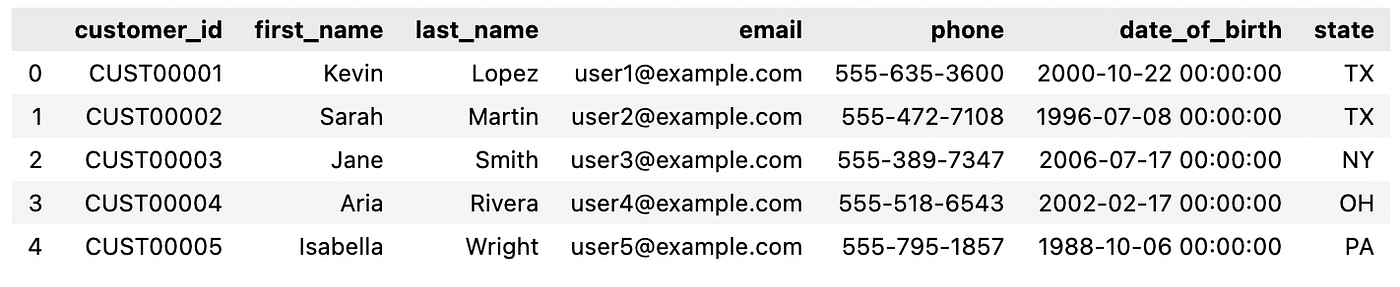
B. Dữ liệu FAQ
B1: Tải dữ liệu
Để chuẩn bị dữ liệu FAQ (Câu hỏi thường gặp), chúng tôi đầu tiên tải bộ dữ liệu InsuranceQA-v2 từ Hugging Face. Đây là một bộ dữ liệu hỏi-đáp trong lĩnh vực bảo hiểm (Nguồn dữ liệu).
Đầu tiên, chúng tôi tải bộ dữ liệu InsuranceQA-v2 (từ thư viện datasets của Hugging Face) và sau đó hợp nhất tất cả các phần thành một DataFrame pandas.
Tiếp theo, chúng tôi kết hợp mỗi câu hỏi và câu trả lời vào một trường văn bản duy nhất là combined, và hiển thị năm hàng đầu tiên.
from datasets import load_dataset
import pandas as pd
# Load the dataset from Hugging Face
ds = load_dataset("deccan-ai/insuranceQA-v2")
# Combine all splits into a single DataFrame
df = pd.concat([split.to_pandas() for split in ds.values()], ignore_index=True)
df["combined"] = "Question: " + df["input"] + " \n Answer: " + df["output"]
# Inspect
print(df.shape)
df.head()
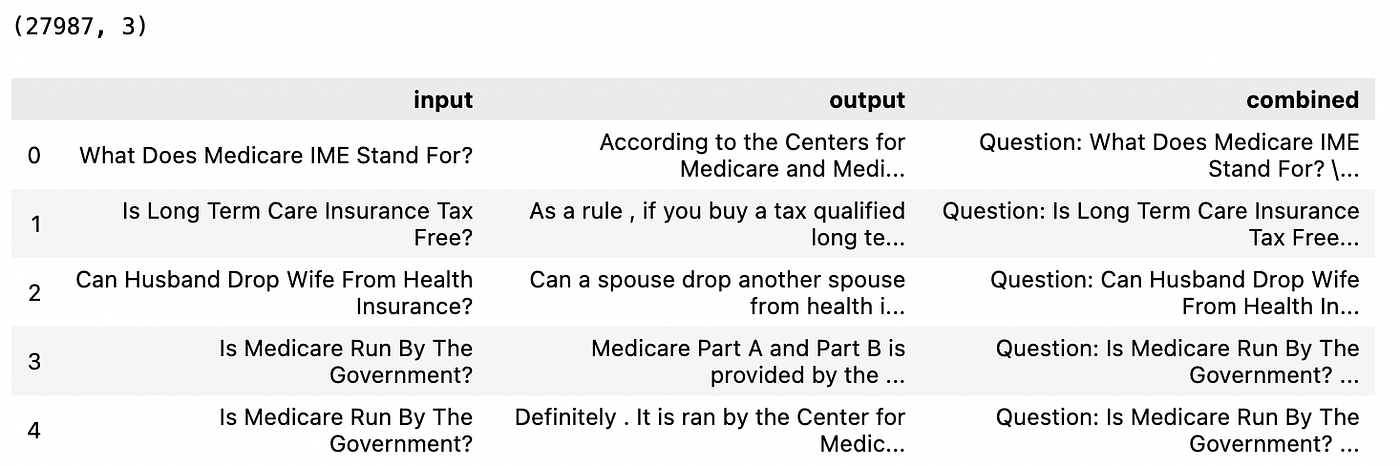 Năm hàng đầu tiên của bộ dữ liệu InsuranceQA-v2
Năm hàng đầu tiên của bộ dữ liệu InsuranceQA-v2
B2: Thiết lập Vector Store: ChromaDB
Đầu tiên, chúng tôi thiết lập kho lưu trữ chromadb bằng PersistentClient và sau đó tạo một collection có tên là insurance_FAQ_collection.
import chromadb
# Setting up the Chromadb
chroma_client = chromadb.PersistentClient(path="./chroma_db")
# Add a collection
collection = chroma_client.get_or_create_collection(name="insurance_FAQ_collection")
Tiếp theo, chúng tôi thêm dữ liệu vào collection.
Ở đây, chúng tôi lấy mẫu 500 cặp câu hỏi và câu trả lời từ toàn bộ bộ dữ liệu cho mục đích thử nghiệm.
Xin lưu ý rằng các embedding sẽ là embedding mặc định từ sentence transformers (all-MiniLM-L6-v2).
# Collection 1 for insurance Q&A Dataset
from tqdm import tqdm
df = df.sample(200, random_state=42).reset_index(drop=True) # For testing, use a smaller subset
# Add data to collection
# here the chroma db will use default embeddings (sentence transformers)
# Split into batches of <= 5000
batch_size = 100
for i in tqdm(range(0, len(df), batch_size)):
batch_df = df.iloc[i:i+batch_size]
collection.add(
documents=batch_df["combined"].tolist(),
metadatas=[{"question": q, "answer": a} for q, a in zip(batch_df["input"], batch_df["output"])],
ids=batch_df.index.astype(str).tolist()
)
Kiểm tra Vector Store:
## Testing the retrieval
query = "What does life insurance cover?"
collection = chroma_client.get_collection(name="insurance_FAQ_collection")
results = collection.query(
query_texts=[query],
n_results=3,
)
for i, m in enumerate(results["metadatas"][0]):
print(f"Result {i+1}:")
print("Distance:", results["distances"][0][i])
print("Q:", m["question"])
print("A:", m["answer"])
print("-" * 50)
Result 1:
Distance: 0.3581928610801697
Q: What Does Life Insurance Typically Cover?
A: Life insurance is intended to provide some monetary assistance in the event that the insured passes away while covered . Life insurance is typically meant as a way for the family of the insured to be financially capable of moving on after the loss . The funds from the policy are intended to help provide for those things that could have possibly been provided -LRB- i.e. pay off debt , pay for college , etc. . . -RRB- by the insured if the insured had not passed . This is a very limited explanation of life insurance , contact a local agent to discuss your wants and needs with this type of coverage .
--------------------------------------------------
Result 2:
Distance: 0.41367289423942566
Q: What Does Life Insurance Typically Cover?
A: Life insurance is designed to pay a determined benefit amount upon the death of the insured . Any cause of death is typically covered except suicide within the first two years of the policy . If it can be proved that fraud was committed in obtaining the policy then only the amount of premiums paid will be returned to the beneficiary .
--------------------------------------------------
Result 3:
Distance: 0.44703125953674316
Q: What Does Life Insurance Not Cover?
A: The only thing that all life insurance policies do not cover is death due to suicide in the first two years of the policy . Some policies will exclude death caused during the commission of a crime , or by acts of war or terrorism . Others could have a stipulation , such as death caused by parachuting , but that will be an exception stated explicitly in your policy for your particular situation . Life insurance pays for death due to old age , anything health related , and accident . This covers the vast majority of causes of death .
--------------------------------------------------
Đọc bài viết khác của tôi để biết thêm về ChromaDB: Hướng dẫn thực hành sử dụng ChromaDB cho RAG và tìm kiếm ngữ nghĩa
Thiết lập giám sát Prompt
Trong bất kỳ ứng dụng GenAI nào, khi có nhiều prompt, việc giám sát chúng trở nên cần thiết.
Chúng tôi sử dụng thư viện mã nguồn mở arize-phoenix (backend OpenTelemetry) để theo dõi và gỡ lỗi nhằm thiết lập hệ thống giám sát.
Thiết lập phoenix_enpoint trong tệp .env như sau:
PHOENIX_COLLECTOR_ENDPOINT=http://127.0.0.1:6006/v1/traces
Sau đó chạy lệnh dưới đây trong terminal:
phoenix serve
Theo mặc định, nó chạy tại:
http://localhost:6006
Sau đó, chúng tôi định nghĩa trace_provider và trace_agent dưới đây để bật tính năng theo dõi ở cấp độ tác tử.
from functools import wraps
import time
from opentelemetry.trace.status import Status, StatusCode
from opentelemetry.trace import get_current_span
from phoenix.otel import register
from dotenv import load_dotenv
load_dotenv()
phoenix_endpoint = os.getenv("PHOENIX_COLLECTOR_ENDPOINT")
tracer_provider = register(
project_name="multi-agent-system",
endpoint=phoenix_endpoint,
auto_instrument=True
)
tracer = tracer_provider.get_tracer(__name__)
# --- Decorator ---
def trace_agent(func):
"""
Decorator to wrap multi-agent functions in a Phoenix span with metadata.
"""
@wraps(func)
def wrapper(*args, **kwargs):
state = args[0] if args else {}
agent_name = func.__name__
with tracer.start_as_current_span(agent_name) as span:
# --- Add standard metadata ---
span.set_attribute("agent.name", agent_name)
span.set_attribute("agent.type", agent_name.replace("_node", ""))
span.set_attribute("user.id", state.get("customer_id", "unknown"))
span.set_attribute("policy.number", state.get("policy_number", "unknown"))
span.set_attribute("claim.id", state.get("claim_id", "unknown"))
span.set_attribute("task", state.get("task", "none"))
span.set_attribute("timestamp", state.get("timestamp", "n/a"))
start_time = time.time()
try:
result = func(*args, **kwargs)
# --- Record execution metadata ---
duration = time.time() - start_time
span.set_attribute("execution.duration_sec", duration)
if isinstance(result, dict):
span.set_attribute("result.keys", list(result.keys()))
span.set_status(Status(StatusCode.OK))
return result
except Exception as e:
span.record_exception(e)
span.set_status(Status(StatusCode.ERROR, str(e)))
raise
return wrapper
Thiết lập OpenAI Client
Chúng tôi định nghĩa OpenAI client yêu cầu openai_api_key. Hãy chắc chắn rằng bạn đã định nghĩa khóa API trong một tệp .env trong repo.
Xin lưu ý, ở đây chúng tôi đang sử dụng mô hình gpt-5-mini. Bạn có thể sử dụng mô hình tùy chọn của mình.
Chúng tôi định nghĩa một hàm nơi LLM có thể tự quyết định gọi công cụ nếu có sẵn. Có hai trường hợp:
Trường hợp 1: Không có công cụ được định nghĩa:
Trong trường hợp này, LLM chỉ đơn giản tạo ra đầu ra cho đầu vào đã cho (prompt)
Đầu vào → LLM → Đầu ra
Trường hợp 2: Công cụ được định nghĩa:
Trong trường hợp này, lược đồ công cụ cũng được truyền cho LLM cùng với prompt.
- Nếu LLM quyết định gọi công cụ, thì công cụ đó sẽ được thực thi cục bộ và sau đó đầu ra của lệnh gọi công cụ lại được đưa vào LLM để tạo câu trả lời cuối cùng.
- Nếu LLM quyết định không gọi công cụ, thì đầu ra đầu tiên là đầu ra cuối cùng.
# Trường hợp 2.1
Đầu vào → LLM → gọi-công-cụ → thực-thi-công-cụ → LLM → đầu ra
# Trường hợp 2.2
Đầu vào → LLM → không-gọi-công-cụ → đầu ra
Tất cả các trường hợp trên cũng được giải thích bằng biểu đồ dưới đây:
 LLM có và không có lệnh gọi công cụ [Ảnh của tác giả]
LLM có và không có lệnh gọi công cụ [Ảnh của tác giả]
from dotenv import load_dotenv
from openai import OpenAI
import json
from typing import List, Dict, Any, Optional
# ✅ Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPEN_AI_KEY")
client = OpenAI(api_key=openai_api_key)
def run_llm(
prompt: str,
tools: Optional[List[Dict]] = None,
tool_functions: Optional[Dict[str, Any]] = None,
model: str = "gpt-5-mini",
) -> str:
"""
Run an LLM request that optionally supports tools.
Args:
prompt (str): The system or user prompt to send.
tools (list[dict], optional): Tool schema list for model function calling.
tool_functions (dict[str, callable], optional): Mapping of tool names to Python functions.
model (str): Model name to use (default: gpt-5-mini).
Returns:
str: Final LLM response text.
"""
# Step 1: Initial LLM call
response = client.chat.completions.create(
model=model,
messages=[{"role": "system", "content": prompt}],
tools=tools if tools else None,
tool_choice="auto" if tools else None
)
message = response.choices[0].message
# Step 2: If no tools or no tool calls, return simple model response
if not getattr(message, "tool_calls", None):
return message.content
# Step 3: Handle tool calls dynamically
if not tool_functions:
return message.content + "\n\n⚠️ No tool functions provided to execute tool calls."
tool_messages = []
for tool_call in message.tool_calls:
func_name = tool_call.function.name
args = json.loads(tool_call.function.arguments or "{}")
tool_fn = tool_functions.get(func_name)
try:
result = tool_fn(**args) if tool_fn else {"error": f"Tool '{func_name}' not implemented."}
except Exception as e:
result = {"error": str(e)}
tool_messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result)
})
# Step 4: Second pass — send tool outputs back to the model
followup_messages = [
{"role": "system", "content": prompt},
{
"role": "assistant",
"content": message.content,
"tool_calls": [
{
"id": tc.id,
"type": tc.type,
"function": {
"name": tc.function.name,
"arguments": tc.function.arguments,
},
} for tc in message.tool_calls
],
},
*tool_messages,
]
final = client.chat.completions.create(model=model, messages=followup_messages)
return final.choices[0].message.content
Trường hợp 1: Gọi LLM không có công cụ
prompt = "Explain the theory of relativity in simple terms in 30 words."
response = run_llm(prompt)
print(response)
Relativity links space and time into spacetime. Special relativity: light speed constant, motion changes measured time and length. General relativity: mass-energy curves spacetime, producing gravity, orbital motion, and observable effects.
Trường hợp 2.1: Gọi LLM với công cụ
def add_numbers(a: int, b: int):
return {"result": a + b}
tools = [{
"type": "function",
"function": {
"name": "add_numbers",
"description": "Add two numbers together",
"parameters": {
"type": "object",
"properties": {
"a": {"type": "integer"},
"b": {"type": "integer"}
},
"required": ["a", "b"]
},
}
}]
prompt = "Please add 3 and 5 using the available tool."
response = run_llm(prompt, tools=tools, tool_functions={"add_numbers": add_numbers})
print(response)
3 + 5 = 8. I used the tool to compute this.
Trường hợp 2.2: Gọi LLM với công cụ nhưng hỏi một câu hỏi không cần gọi công cụ
prompt = "Explain the theory of relativity in simple terms in 30 words."
response = run_llm(prompt, tools=tools, tool_functions={"add_numbers": add_numbers})
print(response)
Relativity explains how space, time, motion, and gravity connect: observers moving differently measure distances, durations, and mass differently; light speed is constant, and gravity curves spacetime, affecting clocks and paths.
Định nghĩa các công cụ cho các tác tử
Bây giờ chúng ta định nghĩa các công cụ có thể được sử dụng bởi các tác tử khác nhau.
**ask_user()**– Nhắc người dùng nhập thông tin và ghi lại phản hồi của họ.**get_policy_details()**– Truy xuất thông tin chi tiết về hợp đồng (và thông tin khách hàng) theo số hợp đồng.**get_claim_status()**– Lấy chi tiết khiếu nại và trạng thái hiện tại bằng ID khiếu nại hoặc số hợp đồng.**get_billing_info()**– Truy xuất thông tin thanh toán hiện tại như số dư, ngày đến hạn và phí bảo hiểm.**get_payment_history()**– Trả về các bản ghi thanh toán gần đây nhất cho một hợp đồng nhất định.**get_auto_policy_details()**– Lấy các chi tiết cụ thể của hợp đồng ô tô như thông tin xe và các khoản khấu trừ.
# =====================================================
# Define the TOOL functions (these run locally)
# =====================================================
import logging
from datetime import datetime
# Set up logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('insurance_agent.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
def ask_user(question: str, missing_info: str = ""):
"""Ask the user for input and return the response."""
logger.info(f"🗣️ Asking user for input: {question}")
if missing_info:
print(f"---USER INPUT REQUIRED---\nMissing information: {missing_info}")
else:
print(f"---USER INPUT REQUIRED---")
answer = input(f"{question}: ")
logger.info(f"✅ User provided response: {answer}")
return {"context": answer, "source": "User Input"}
def get_policy_details(policy_number: str) -> Dict[str, Any]:
"""Fetch a customer's policy details by policy number"""
logger.info(f"🔍 Fetching policy details for: {policy_number}")
conn = sqlite3.connect('insurance_support.db')
cursor = conn.cursor()
cursor.execute("""
SELECT p.*, c.first_name, c.last_name
FROM policies p
JOIN customers c ON p.customer_id = c.customer_id
WHERE p.policy_number = ?
""", (policy_number,))
result = cursor.fetchone()
conn.close()
if result:
logger.info(f"✅ Policy found: {policy_number}")
columns = [desc[0] for desc in cursor.description]
return dict(zip(columns, result))
logger.warning(f"❌ Policy not found: {policy_number}")
return {"error": "Policy not found"}
def get_claim_status(claim_id: str = None, policy_number: str = None) -> Dict[str, Any]:
"""Get claim status and details"""
logger.info(f"🔍 Fetching claim status - Claim ID: {claim_id}, Policy: {policy_number}")
conn = sqlite3.connect('insurance_support.db')
cursor = conn.cursor()
if claim_id:
cursor.execute("""
SELECT c.*, p.policy_type
FROM claims c
JOIN policies p ON c.policy_number = p.policy_number
WHERE c.claim_id = ?
""", (claim_id,))
elif policy_number:
cursor.execute("""
SELECT c.*, p.policy_type
FROM claims c
JOIN policies p ON c.policy_number = p.policy_number
WHERE c.policy_number = ?
ORDER BY c.claim_date DESC LIMIT 3
""", (policy_number,))
result = cursor.fetchall()
conn.close()
if result:
logger.info(f"✅ Found {len(result)} claim(s)")
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in result]
logger.warning("❌ No claims found")
return {"error": "Claim not found"}
def get_billing_info(policy_number: str = None, customer_id: str = None) -> Dict[str, Any]:
"""Get billing information including current balance and due dates"""
logger.info(f"🔍 Fetching billing info - Policy: {policy_number}, Customer: {customer_id}")
conn = sqlite3.connect('insurance_support.db')
cursor = conn.cursor()
if policy_number:
cursor.execute("""
SELECT b.*, p.premium_amount, p.billing_frequency
FROM billing b
JOIN policies p ON b.policy_number = p.policy_number
WHERE b.policy_number = ? AND b.status = 'pending'
ORDER BY b.due_date DESC LIMIT 1
""", (policy_number,))
elif customer_id:
cursor.execute("""
SELECT b.*, p.premium_amount, p.billing_frequency
FROM billing b
JOIN policies p ON b.policy_number = p.policy_number
WHERE p.customer_id = ? AND b.status = 'pending'
ORDER BY b.due_date DESC LIMIT 1
""", (customer_id,))
result = cursor.fetchone()
conn.close()
if result:
logger.info("✅ Billing info found")
columns = [desc[0] for desc in cursor.description]
return dict(zip(columns, result))
logger.warning("❌ Billing info not found")
return {"error": "Billing information not found"}
def get_payment_history(policy_number: str) -> List[Dict[str, Any]]:
"""Get payment history for a policy"""
logger.info(f"🔍 Fetching payment history for policy: {policy_number}")
conn = sqlite3.connect('insurance_support.db')
cursor = conn.cursor()
cursor.execute("""
SELECT p.payment_date, p.amount, p.status, p.payment_method
FROM payments p
JOIN billing b ON p.bill_id = b.bill_id
WHERE b.policy_number = ?
ORDER BY p.payment_date DESC LIMIT 10
""", (policy_number,))
results = cursor.fetchall()
conn.close()
if results:
logger.info(f"✅ Found {len(results)} payment records")
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in results]
logger.warning("❌ No payment history found")
return []
def get_auto_policy_details(policy_number: str) -> Dict[str, Any]:
"""Get auto-specific policy details including vehicle info and deductibles"""
logger.info(f"🔍 Fetching auto policy details for: {policy_number}")
conn = sqlite3.connect('insurance_support.db')
cursor = conn.cursor()
cursor.execute("""
SELECT apd.*, p.policy_type, p.premium_amount
FROM auto_policy_details apd
JOIN policies p ON apd.policy_number = p.policy_number
WHERE apd.policy_number = ?
""", (policy_number,))
result = cursor.fetchone()
conn.close()
if result:
logger.info("✅ Auto policy details found")
columns = [desc[0] for desc in cursor.description]
return dict(zip(columns, result))
logger.warning("❌ Auto policy details not found")
return {"error": "Auto policy details not found"}
Định nghĩa các Prompt:
Bây giờ, hãy thiết lập phần quan trọng nhất của các tác tử: Prompt. Chúng tôi định nghĩa các prompt cụ thể cho mỗi tác tử.
SUPERVISOR_PROMPT = """
You are the SUPERVISOR AGENT managing a team of insurance support specialists.
Your role:
1. Go throught the conversatio history and understand the current requirement.
2. Understand the user's intent and context.
3. Evaluate available information and decide if clarification is needed.
4. Route to the appropriate specialist agent.
5. End conversation when the task is complete.
AVAILABLE INFORMATION:
- Conversation History: {conversation_history}
CRITICAL RULES:
- If policy number is already available, DO NOT ask for it again
- If customer ID is already available, DO NOT ask for it again
- Only use ask_user tool if ESSENTIAL information is missing. Keep the clarification questions minimal (within 15 words) and specific.
- Route directly to appropriate agent if you have sufficient information
- Check the conversation history carefully - policy numbers or customer IDs mentioned earlier in the conversation should be considered available
- If the user just provided information in response to your clarification question, that information is NOW available and should not be asked for again
Specialist agents:
- policy_agent → policy details, coverage, endorsements
- billing_agent → billing, payments, premium questions
- claims_agent → claim filing, tracking, settlements
- human_escalation_agent → for complex cases
- general_help_agent → for general questions
CLARIFICICATION QUESTION GUIDELINES:
1. Keep questions concise (<=15 words)
2. Ask only for ESSENTIAL missing info (policy number, customer ID, claim ID)
EVALUATION INSTRUCTIONS:
- Review the conversation history thoroughly.
- Agents answers are also part of the conversation history.
- If agents ask for more information, use ask_user tool to get it from the user.
- Evaluate the anwer of the agent carefully to see if the user's question is fully answered.
- If user's question is fully answered, route to 'end'.
DECISION GUIDELINES:
1. Policy/coverage questions → policy_agent
2. Billing/payment questions → billing_agent
3. Claims questions → claims_agent
4. General questions (example: In general, what does life insurance cover?) → general_help_agent
5. Complete + answered → end
TASK GENERATION GUIDELINES:
1. If routing to a specialist, summarize the user's main request.
2. Keep the policy number, customer ID, claim ID (if applicable and available) in Task also.
Respond in JSON:
{{
"next_agent": "<agent_name or 'end'>",
"task": "<concise task description>",
"justification": "<why this decision>"
}}
Only use ask_user tool if absolutely necessary.
"""
POLICY_AGENT_PROMPT = """
You are a **Policy Specialist Agent** for an insurance company.
Assigned Task:
{task}
Responsibilities:
1. Policy details, coverage, and deductibles
2. Vehicle info and auto policy specifics
3. Endorsements and policy updates
Tools:
- get_policy_details
- get_auto_policy_details
Context:
- Policy Number: {policy_number}
- Customer ID: {customer_id}
- Conversation History: {conversation_history}
Instructions:
- Use tools to retrieve information as needed.
- Ask politely for missing details.
- Keep responses professional and clear.
"""
BILLING_AGENT_PROMPT = """
You are a **Billing Specialist Agent**.
Assigned Task:
{task}
Responsibilities:
1. Billing statements, payments, and invoices
2. Premiums, due dates, and payment history
Instructions:
- Use tools to retrieve billing and payment information.
- Ask politely for any missing details.
- Just answer the questions that are asked. Don't provide extra information.
- If you think the question is answered, don't ask for more information. Just retrun with the specific answer.
Tools:
- get_billing_info
- get_payment_history
Context:
- Conversation History: {conversation_history}
"""
CLAIMS_AGENT_PROMPT = """
You are a **Claims Specialist Agent**.
Assigned Task:
{task}
Responsibilities:
1. Retrieve or update claim status
2. Help file new claims
3. Explain claim process and settlements
Tools:
- get_claim_status
Context:
- Policy Number: {policy_number}
- Claim ID: {claim_id}
- Conversation History: {conversation_history}
"""
GENERAL_HELP_PROMPT = """
You are a **General Help Agent** for insurance customers.
Assigned Task:
{task}
Goal:
Answer FAQs and explain insurance topics in simple, clear, and accurate language.
Context:
- Conversation History: {conversation_history}
Retrieved FAQs from the knowledge base:
{faq_context}
Instructions:
1. Review the retrieved FAQs carefully before answering.
2. If one or more FAQs directly answer the question, use them to construct your response.
3. If the FAQs are related but not exact, summarize the most relevant information.
4. If no relevant FAQs are found, politely inform the user and provide general guidance.
5. Keep responses clear, concise, and written for a non-technical audience.
6. Do not fabricate details beyond what’s supported by the FAQs or obvious domain knowledge.
7. End by offering further help (e.g., “Would you like to know more about this topic?”).
Now provide the best possible answer for the user’s question.
"""
HUMAN_ESCALATION_PROMPT = """
You are handling a **Customer Escalation**.
Assigned Task:
{task}
Conversation History: {conversation_history}
Respond empathetically, acknowledge the request for a human, and confirm that a human representative will join shortly.
Don't attempt to answer any questions or provide information yourself.
Don't ask any further questions. Just acknowledge the escalation request.
"""
FINAL_ANSWER_PROMPT = """
The user asked: "{user_query}"
The specialist agent provided this detailed response:
{specialist_response}
Your task: Create a FINAL, CLEAN response that:
1. Directly answers the user's original question in a friendly tone
2. Includes only the most relevant information (remove technical details)
3. Is concise and easy to understand
4. Ends with a polite closing
Important: Do NOT include any internal instructions, tool calls, or technical details.
Just provide the final answer that the user should see.
Final response:
"""
Những prompt này sẽ được sử dụng trong phần tiếp theo khi chúng ta định nghĩa các tác tử.
Thiết lập các tác tử
Bây giờ hãy thiết lập chính các tác tử.
1. Tác tử Giám sát (Supervisor Agent)
Đây là tác tử trung tâm điều phối với người dùng và tất cả các tác tử khác. Tác tử Giám sát:
- Phân tích lịch sử cuộc trò chuyện để xác định yêu cầu hiện tại của người dùng, các chi tiết đã cung cấp trước đó (như số hợp đồng hoặc ID khách hàng), và bất kỳ thông tin nào còn thiếu.
- Xác định bước tiếp theo bằng cách định tuyến truy vấn đến tác tử chuyên gia phù hợp — chẳng hạn như
policy_agent,billing_agent, hoặcclaims_agent— dựa trên ý định được phát hiện. - Quản lý luồng làm rõ bằng cách gọi công cụ
ask_userđể yêu cầu chỉ những chi tiết thiết yếu còn thiếu một cách ngắn gọn, có mục tiêu. - Theo dõi tiến trình lặp để ngăn chặn các vòng lặp vô hạn và chuyển giao cho một nhân viên hỗ trợ con người nếu vấn đề vẫn chưa được giải quyết sau nhiều lần lặp của giám sát viên.
- Duy trì và cập nhật lịch sử cuộc trò chuyện với tất cả các trao đổi giữa trợ lý và người dùng, đảm bảo ngữ cảnh đầy đủ được bảo toàn cho các tác tử sau đó.
@trace_agent # used to trace the prompt level monitoring
def supervisor_agent(state):
print("---SUPERVISOR AGENT---")
# Increment iteration counter
n_iter = state.get("n_iteration", 0) + 1
state["n_iteration"] = n_iter
print(f"🔢 Supervisor iteration: {n_iter}")
# Force end if iteration limit reached
# Escalate to human support if iteration limit reached
if n_iter >= 3:
print("⚠️ Maximum supervisor iterations reached — escalating to human agent")
updated_history = (
state.get("conversation_history", "")
+ "\nAssistant: It seems this issue requires human review. Escalating to a human support specialist."
)
return {
"escalate_to_human": True,
"conversation_history": updated_history,
"next_agent": "human_escalation_agent",
"n_iteration": n_iter
}
# Check if we're coming from a clarification
if state.get("needs_clarification", False):
user_clarification = state.get("user_clarification", "")
print(f"🔄 Processing user clarification: {user_clarification}")
# Update conversation history with the clarification exchange
clarification_question = state.get("clarification_question", "")
updated_conversation = state.get("conversation_history", "") + f"\nAssistant: {clarification_question}\nUser: {user_clarification}"
# Update state to clear clarification flags and update history
updated_state = state.copy()
updated_state["needs_clarification"] = False
updated_state["conversation_history"] = updated_conversation
# Clear clarification fields
if "clarification_question" in updated_state:
del updated_state["clarification_question"]
if "user_clarification" in updated_state:
del updated_state["user_clarification"]
return updated_state
user_query = state["user_input"]
conversation_history = state.get("conversation_history", "")
print(f"User Query: {user_query}")
print(f"Conversation History: {conversation_history}")
# Include the ENTIRE conversation history in the prompt
full_context = f"Full Conversation:\n{conversation_history}"
prompt = SUPERVISOR_PROMPT.format(
conversation_history=full_context, # Use full context instead of just history
)
tools = [
{
"type": "function",
"function": {
"name": "ask_user",
"description": "Ask the user for clarification or additional information when their query is unclear or missing important details. ONLY use this if essential information like policy number or
Theo dõi trên X