AI Agents: Khóa học toàn diện

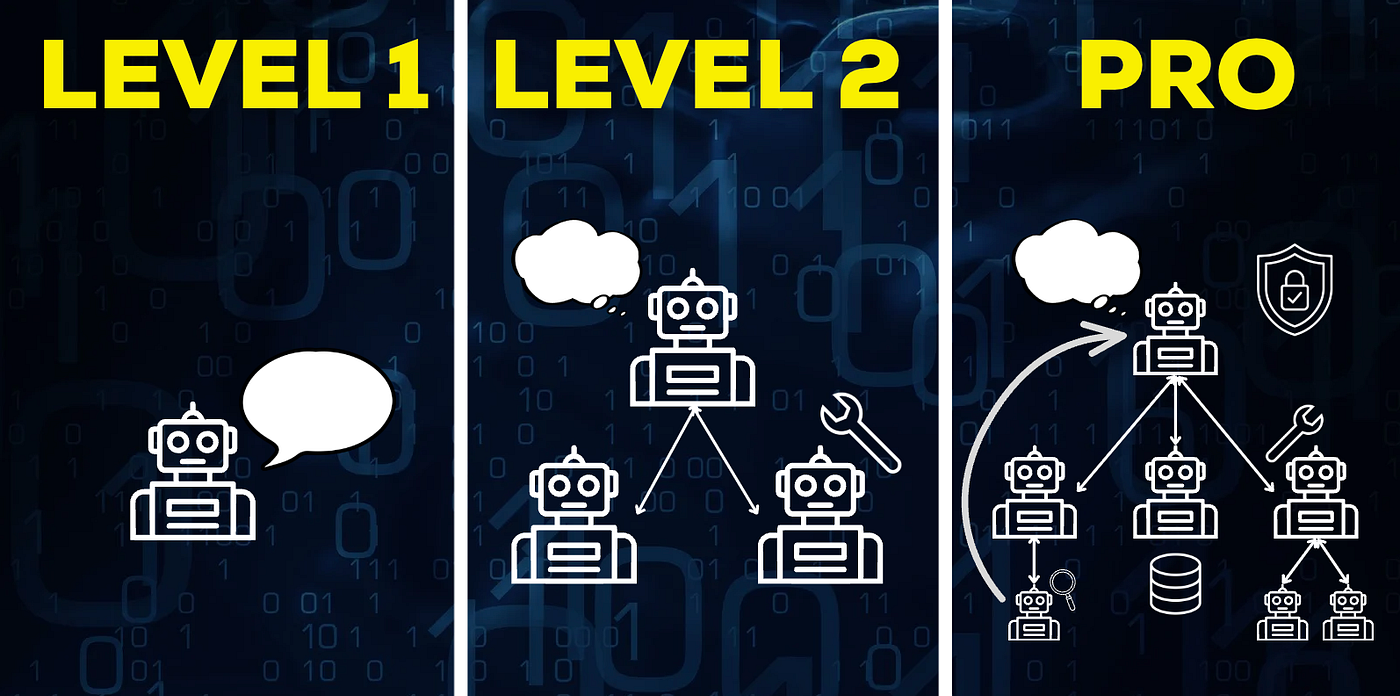
Nếu bạn đã theo dõi lĩnh vực AI trong năm 2025, có lẽ bạn đã nhận thấy mọi người đều đang nói về các agent (tác tử). Và điều đó hoàn toàn có lý do. Các AI agent có thể xử lý mọi thứ, từ những công việc đơn giản hàng ngày đến các quy trình làm việc phức tạp với nhiều agent ở quy mô doanh nghiệp.
Và đây mới chỉ là sự khởi đầu. Chúng ta sắp chứng kiến nhiều sự đổi mới hơn nữa trong lĩnh vực này.
Nếu bạn là người mới ở đây, tôi là Marina. Tôi là một Nhà khoa học Ứng dụng Cấp cao tại Amazon, chuyên về Gen AI, và hôm nay tôi sẽ phân tích mọi thứ bạn cần biết về việc xây dựng và làm việc với các AI agent.
Tôi đã nghiên cứu rất sâu về chủ đề này. Tôi đã tham gia nhiều khóa học khác nhau, đọc sách và tự xây dựng các agent của riêng mình. Ghi chú nghiên cứu của tôi dài khoảng 150 trang, và tôi đã cô đọng tất cả lại cho bạn trong một bài viết duy nhất.
Đây là cách chúng ta sẽ phân tích vấn đề:
Đầu tiên, những điều cơ bản. AI agent là gì, các khái niệm cốt lõi là gì, và bạn thực sự có thể sử dụng chúng ở đâu? Chúng ta cũng sẽ đề cập đến một số lựa chọn không cần code nếu bạn muốn bắt đầu thử nghiệm mà không cần viết bất kỳ dòng code nào.
Tiếp theo, cấp độ trung cấp. Chúng ta sẽ đi vào việc xây dựng và đánh giá các hệ thống đa agent để giải quyết các vấn đề thực tế. Tôi sẽ demo một hệ thống agent mà tôi đã tạo ra và hiện đang giúp tôi tiết kiệm vài giờ làm việc mỗi tuần.
Sau đó là nâng cao. Cần những gì để thực sự xây dựng các hệ thống agent đáng tin cậy trong môi trường production?
Và cuối cùng, một phần thưởng dành cho các lập trình viên muốn tìm hiểu sâu và hiểu rõ cách các công cụ như Claude Code hoạt động bên trong.
Dù bạn là người không chuyên về kỹ thuật chỉ muốn tự động hóa một phần công việc của mình hay bạn đang xây dựng các hệ thống AI cho công ty, bài viết này đều có điều gì đó dành cho bạn.
Hãy cùng bắt đầu nào.
CƠ BẢN
Agent là gì?
Được rồi, hãy bắt đầu với những điều cơ bản nhất: AI agent thực sự là gì?
Đây là cách nghĩ đơn giản nhất. Hãy tưởng tượng bạn cần viết một bài luận. Nếu bạn sử dụng một prompt LLM truyền thống, bạn sẽ nói, "Này ChatGPT, viết cho tôi một bài luận về cách bắt đầu tập gym," và nó sẽ viết toàn bộ bài luận trong một lần từ đầu đến cuối.
Nhưng đó không phải là cách bạn và tôi thực sự viết một bài luận, phải không? Chúng ta không chỉ tạo ra một bản nháp hoàn hảo ngay từ lần đầu. Chúng ta lên kế hoạch, lập dàn ý, nghiên cứu, viết một bản nháp lộn xộn, đọc lại và sửa đổi. Đó là một quá trình.
Đó chính là những gì AI agentic (AI có tính tác tử) làm. Thay vì yêu cầu AI làm mọi thứ trong một lượt duy nhất, bạn để nó làm việc lặp đi lặp lại như cách con người làm.

Vậy điều đó thực sự trông như thế nào?
Hãy tiếp tục với ví dụ viết bài luận của chúng ta. Đây là cách một agent sẽ xử lý nó:
Đầu tiên, nó bắt đầu với một dàn ý. Nó xác định cấu trúc trước khi đi vào viết. Các điểm chính là gì? Thứ tự nào hợp lý?
Sau đó, nó xác định thông tin cần thiết từ dàn ý và thực sự đi lấy thông tin đó.
Nó có thể tìm kiếm trên web, lấy dữ liệu từ các API, hoặc tải xuống các nguồn tài liệu liên quan, và sau đó sử dụng thông tin này để viết bản nháp đầu tiên của bài luận.
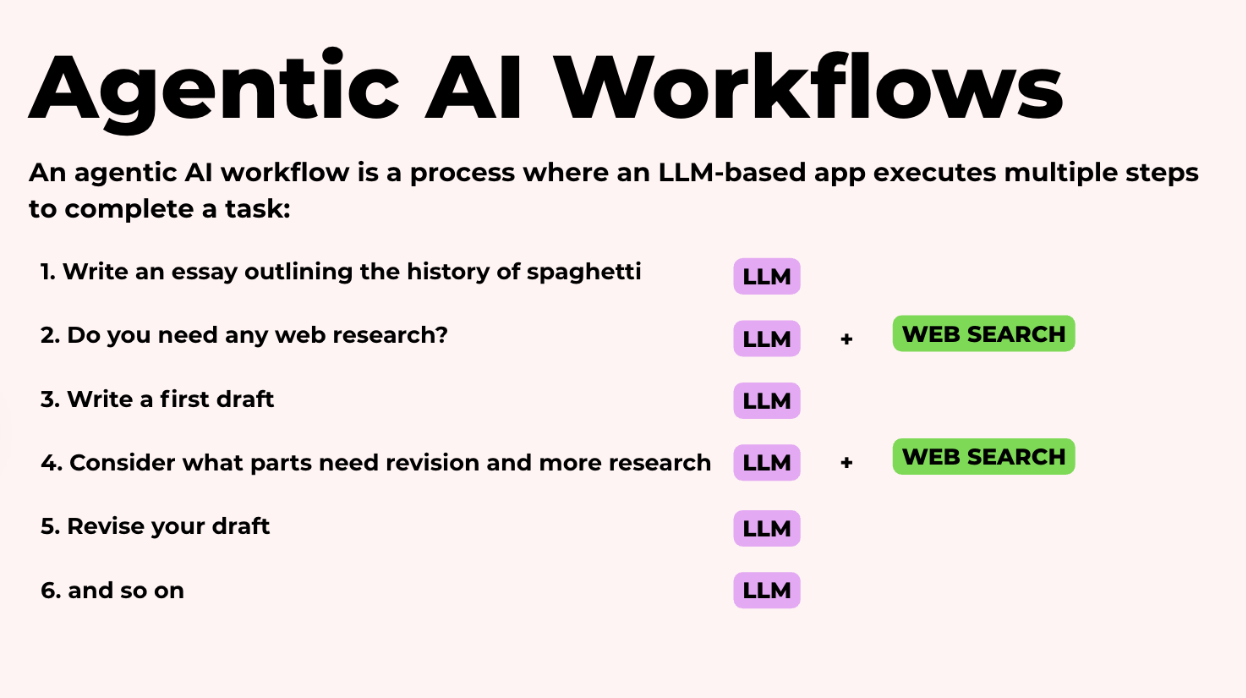
Nhưng điều thú vị là nó không dừng lại ở đó. Agent tự suy ngẫm về công việc của mình và sửa đổi để làm những việc như củng cố các lập luận yếu, bổ sung thông tin còn thiếu, hoặc cải thiện sự mạch lạc.
Đây là điều mà mọi người gọi là vòng lặp ReAct. Mô hình suy luận (Reason) về việc cần làm tiếp theo, hành động (Act) (thường bằng cách gọi một công cụ, chúng ta sẽ nói về điều này sau), quan sát (Observe) kết quả, sau đó hoặc đưa ra câu trả lời cho bạn hoặc quay lại vòng lặp để suy luận một lần nữa.
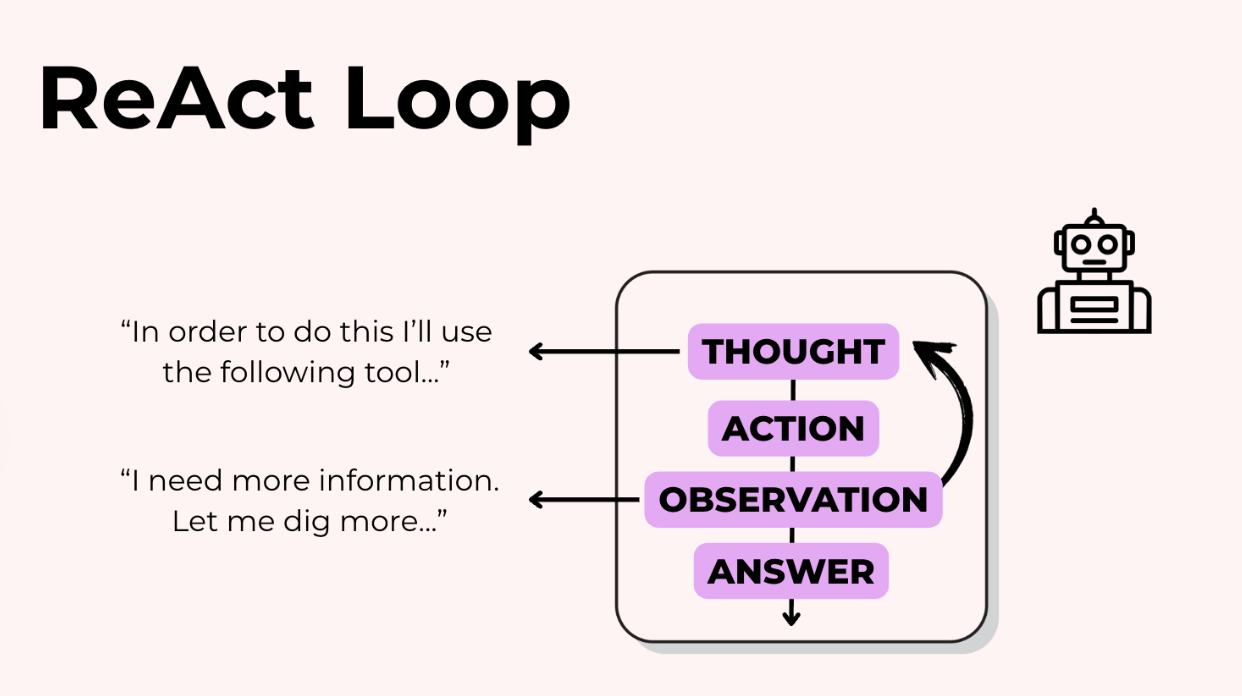
Điều này hoạt động vì mỗi lượt đi qua sẽ tăng thêm chiều sâu. Bạn có được khả năng suy luận mạnh mẽ hơn, ít ảo giác (hallucination) hơn, và tổ chức tốt hơn, tất cả những thứ bị mất đi khi bạn cố gắng làm mọi thứ trong một lần.
Cách tiếp cận này hoạt động tốt ở bất cứ đâu bạn cần công việc cẩn thận, chính xác với nguồn trích dẫn hợp lệ. Bạn có thể nghĩ đến các lĩnh vực như nghiên cứu pháp lý nơi bạn cần trích dẫn các vụ án cụ thể, tài liệu chăm sóc sức khỏe, hoặc các hệ thống hỗ trợ khách hàng cần tra cứu chi tiết tài khoản trước khi phản hồi.
Tất nhiên, sự chuyên môn hóa và độ chính xác cao hơn đi kèm với chi phí về độ phức tạp. Vì vậy, điều này đặt ra một câu hỏi rõ ràng: những loại công việc nào thực sự đáng để xây dựng agent?
Agent giỏi trong những loại công việc nào?
Một số công việc phù hợp với agent, một số thì không. Hãy xem qua một vài ví dụ, từ đơn giản nhất đến phức tạp nhất.
Một ví dụ rất đơn giản về hệ thống agent có thể là trích xuất các trường thông tin chính từ hóa đơn, sau đó lưu chúng vào cơ sở dữ liệu. Các công việc có quy trình rõ ràng, lặp đi lặp lại như thế này là hoàn hảo cho các agent.
Một ví dụ có độ phức tạp trung bình có thể là trả lời email của khách hàng. Agent tra cứu đơn hàng, kiểm tra hồ sơ khách hàng và soạn thảo một phản hồi để con người xem xét.
Một cấp độ cao hơn là một agent dịch vụ khách hàng hoàn chỉnh xử lý các câu hỏi như "Bạn có còn quần jean xanh không?" hoặc "Làm thế nào để trả lại món hàng này?" Đối với việc trả hàng, agent cần xác minh giao dịch mua, kiểm tra chính sách, xác nhận xem có được phép trả hàng hay không, sau đó hướng dẫn toàn bộ quy trình trả hàng có nhiều bước. Agent phải tự tìm ra các bước cần làm, chứ không chỉ tuân theo một kịch bản có sẵn.
Một cách hữu ích để suy nghĩ về những trường hợp sử dụng nào hợp lý cho agent là sử dụng một ma trận có hai trục: độ phức tạp và độ chính xác.
Một số vấn đề vừa có độ phức tạp cao vừa yêu cầu độ chính xác cao như điền tờ khai thuế.
Những vấn đề khác phức tạp nhưng không cần độ chính xác hoàn hảo. Trong trường hợp này, bạn có thể nghĩ đến việc viết và kiểm tra tóm tắt các bài giảng.
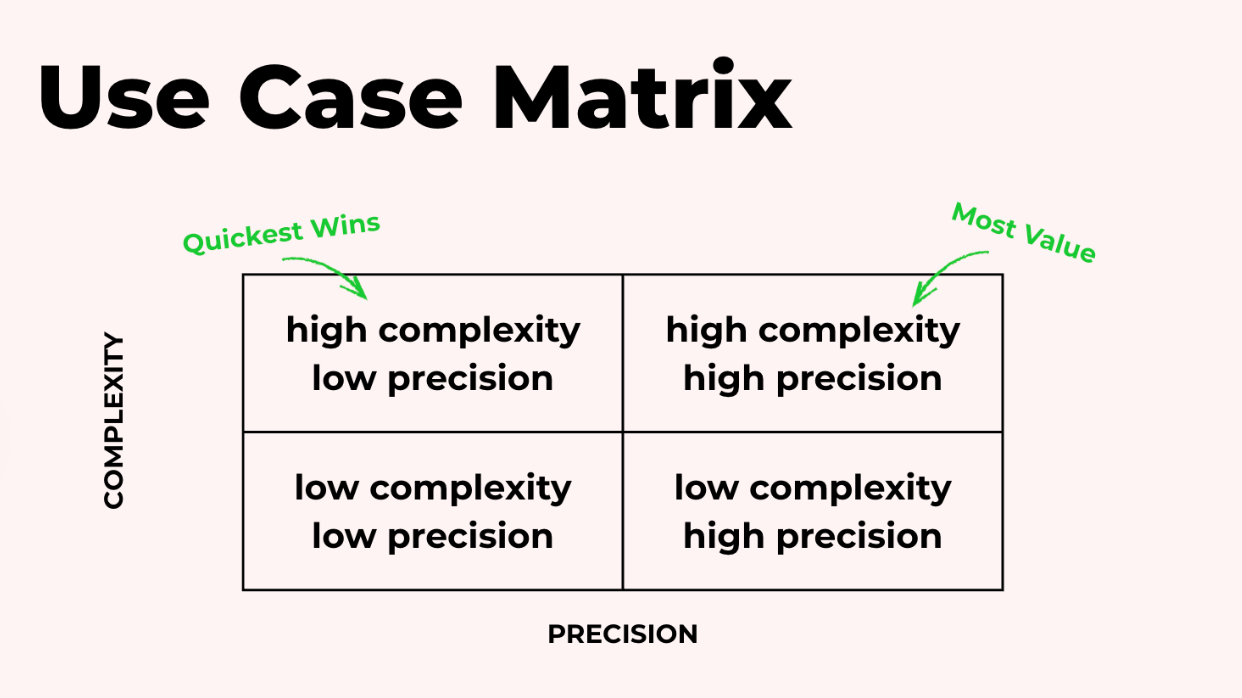
Giá trị lớn nhất thường đến từ công việc có độ phức tạp cao, và những thành công ban đầu nhanh nhất thường nằm ở phía có độ chính xác thấp hơn. Đó là lý do tại sao góc phần tư phức tạp cao, độ chính xác thấp thường là điểm khởi đầu thông minh. Bạn tận dụng được lợi thế từ việc tự động hóa một việc khó khăn mà không bị cản trở bởi yêu cầu đầu ra phải hoàn hảo mọi lúc.
Tóm lại, các agent thực sự tỏa sáng khi công việc đòi hỏi sự lặp lại, nghiên cứu hoặc các quy trình nhiều bước. Thường thì nên bắt đầu với các công việc phức tạp có thể chấp nhận độ chính xác thấp hơn một chút.
Phổ tự chủ
Được rồi, bây giờ bạn đã biết agent giỏi trong việc gì, hãy nói về cách thực sự xây dựng chúng. Và quyết định lớn đầu tiên bạn cần đưa ra là bạn muốn trao cho agent của mình bao nhiêu quyền tự chủ?
Hãy nghĩ về điều này như một phổ.
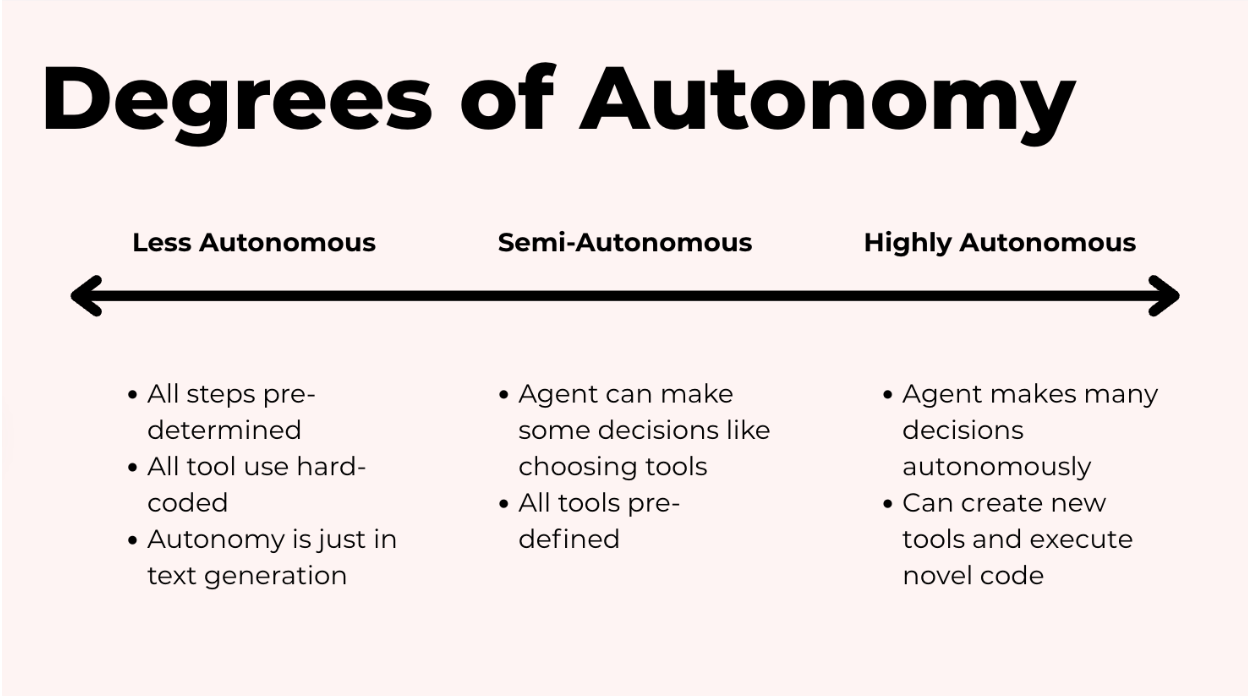
Ở một đầu, bạn có các agent theo kịch bản (scripted agents) nơi bạn mã hóa cứng từng bước. Ví dụ, đối với ví dụ viết bài luận của chúng ta, có thể là đầu tiên tạo các thuật ngữ tìm kiếm, gọi tìm kiếm web, lấy các trang, sau đó viết bài luận. Xong. Nó có tính xác định, có thể dự đoán và dễ kiểm soát. Công việc duy nhất của mô hình là tạo ra văn bản thực tế vì bạn đã quyết định mọi thứ khác.
Ở đầu kia, bạn có các agent có tính tự chủ cao. Bây giờ LLM quyết định xem có nên tìm kiếm trên Google, các trang tin tức hay các bài báo nghiên cứu. Nó tự tìm ra số lượng trang cần lấy, có nên chuyển đổi PDF hay không, và có nên suy ngẫm và sửa đổi hay không. Nó thậm chí có thể viết các hàm mới và chạy chúng. Điều này mạnh mẽ hơn, nhưng cũng khó dự đoán và khó kiểm soát hơn.
Trong thực tế, hầu hết các agent trong thế giới thực đều nằm ở đâu đó ở giữa và là bán tự chủ. Agent chọn từ các công cụ bạn đã xác định và đưa ra quyết định trong các giới hạn bạn đặt ra.
Kỹ thuật ngữ cảnh (Context Engineering)
Nhưng làm thế nào một agent biết được có những công cụ nào hoặc làm thế nào để đưa ra quyết định?
Đây là một thứ gọi là "kỹ thuật ngữ cảnh" (context engineering), đó là khi bạn quyết định agent có những thông tin gì. Điều này bao gồm những thứ như bối cảnh của nhiệm vụ, vai trò của agent, bộ nhớ về các hành động trong quá khứ và các công cụ có sẵn.
Nếu bạn kết hợp tất cả ngữ cảnh này lại, ngữ cảnh này sẽ hướng một mô hình không xác định đến các kết quả nhất quán, chất lượng cao.
Đó là nền tảng thực tế của "trí thông minh" trong các agent. Nó không chỉ nằm ở mô hình. Mà là cách bạn thiết kế ngữ cảnh xung quanh nó. Chúng ta sẽ nói nhiều hơn về các thành phần này trong suốt khóa học.
Phân rã nhiệm vụ (Task Decomposition)
Khi agent đã có ngữ cảnh của mình, đã đến lúc xác định các nhiệm vụ mà nó phải thực hiện. Việc xác định các nhiệm vụ này được cho là điều quan trọng nhất bạn sẽ học về việc xây dựng agent.
Hãy bắt đầu với cách bạn sẽ thực hiện nhiệm vụ. Sau đó, với mỗi bước, hãy tự hỏi: "Một LLM có thể làm điều này không? Một đoạn code nhỏ? Một API?" Nếu câu trả lời là không, hãy chia nhỏ nó hơn nữa cho đến khi có thể.
Hãy tiếp tục với ví dụ xây dựng một agent để viết bài luận.
Hãy nghĩ về cách bạn sẽ thực sự viết, sau đó tìm ra cách một AI có thể thực hiện nhiệm vụ đó. Nó có thể diễn ra như sau:
- Lập dàn ý bằng LLM
- Tạo thuật ngữ tìm kiếm bằng LLM, sau đó gọi API tìm kiếm
- Lấy các trang bằng một Công cụ (Tool)
- Viết bản nháp bằng LLM sử dụng các nguồn đó
- Tự phê bình bản nháp bằng LLM để suy ngẫm và liệt kê các thiếu sót
- Và sửa đổi bằng LLM
Mỗi bước đều nhỏ, có thể kiểm tra và rõ ràng. Khi đầu ra không đủ tốt, bạn biết chính xác bước nào cần cải thiện.
TRUNG CẤP
Đánh giá
Được rồi, bây giờ chúng ta đã có những kiến thức cơ bản và đang chuyển sang cấp độ trung cấp.
Chúng ta sẽ bắt đầu với một thứ khá nhàm chán. Nhưng, đây là thứ phân biệt người làm cho vui và dân chuyên nghiệp: Cách bạn đo lường hiệu suất của nó.
Đôi khi, việc đánh giá có thể đơn giản như đo số lần đầu ra của bạn là chính xác. Nếu tôi hỏi chatbot dịch vụ khách hàng của mình xem chúng ta có một mặt hàng nào đó trong kho không, nó có trả lời đúng không.
Nhưng không phải mọi thứ đều rõ ràng như vậy. Hãy nghĩ về agent viết bài luận của chúng ta. Làm thế nào để bạn đo lường xem bài luận có thực sự tốt hay không?
Một cách tiếp cận là sử dụng một LLM thứ hai để đánh giá đầu ra. Hãy để nó xếp hạng mỗi bài luận trên thang điểm từ 1 đến 5 về chất lượng bằng cách sử dụng một thang điểm nhất quán.

Bạn có thể đánh giá hệ thống của mình ở cấp độ thành phần để đảm bảo mỗi bước riêng lẻ hoạt động tốt, và đánh giá từ đầu đến cuối để phán xét chất lượng cuối cùng của toàn bộ hệ thống.
Nếu bạn thấy hệ thống không hoạt động tốt như mong muốn, một bước đầu tiên là kiểm tra các bước trung gian, được gọi là trace (dấu vết). Điều này bao gồm những thứ như các truy vấn tìm kiếm mà agent đã viết, các bản nháp và các bước suy nghĩ. Nếu bạn đọc qua những thứ này, bạn có thể nhận thấy các mẫu như truy vấn quá chung chung, hoặc bước sửa đổi không nhận được đúng phần phê bình.
Những quan sát đó sẽ trở thành các bài đánh giá tiếp theo hoặc các bản sửa lỗi tiếp theo của bạn.
Điều quan trọng là bạn phải bắt đầu đánh giá ngay lập tức, nhưng cũng đừng lo lắng về việc có một hệ thống đánh giá hoàn hảo ngay từ đầu. Bạn có thể làm cho một thứ gì đó hoạt động nhanh chóng và lặp lại theo thời gian.
Bộ nhớ (Memory)
Bây giờ chúng ta đã có một hệ thống đơn giản và một cách nào đó để đo lường hiệu suất, đã đến lúc thực sự làm việc để cải thiện hiệu suất đó. Bộ nhớ là một cách rất phổ biến để làm điều này.
Bộ nhớ là thứ cho phép một agent nhớ những gì đã hoạt động, những gì đã thất bại, và những gì cần làm khác đi vào lần sau, để nó thực sự cải thiện sau mỗi lần chạy. Bạn có thể có bộ nhớ ngắn hạn mà các agent sử dụng để ghi lại công việc của chúng khi đang làm. Trong các hệ thống đa agent, các agent khác có thể đọc những ghi chú đó. Sau khi agent hoàn thành một nhiệm vụ, nó có thể suy ngẫm về những gì đã làm, so sánh kết quả với những gì được mong đợi, tìm ra những gì đã làm tốt và những gì không, và lưu trữ những bài học đó vào bộ nhớ dài hạn.
Lần chạy tiếp theo, nó sẽ tải những bài học đó lên và áp dụng chúng.
Điều này có thể được sử dụng để "huấn luyện" các agent, tương tự như học có giám sát. Bạn có thể đưa ra phản hồi cho agent về công việc của nó để theo thời gian, mỗi lần chạy đều cải thiện về chất lượng. Tôi sẽ cho bạn xem một ví dụ về điều đó trong phần demo ở cuối phần này.
Vì vậy, bộ nhớ là động và được cập nhật sau mỗi lần chạy. Mặt khác, kiến thức là tài liệu tham khảo tĩnh bạn tải lên từ đầu. PDF, CSV, tài liệu, hoặc quyền truy cập vào cơ sở dữ liệu của bạn. Bạn cung cấp nó cho agent một lần, và nó có thể lấy từ thư viện đó bất cứ khi nào cần trích dẫn một điều gì đó chính xác.
Rào chắn (Guardrails)
Khi chúng ta đã thiết lập một agent với nhiệm vụ, kiến thức và bộ nhớ của nó, chúng ta đã sẵn sàng để nó tung hoành! Phải không?
Chưa hẳn. Có một bước rất quan trọng mà chúng ta chưa nói đến.
Bởi vì các LLM là không xác định, chúng có thể mắc lỗi. Có thể chúng viết một cái gì đó sai sự thật, hoặc sai định dạng.
Để ngăn chặn các vấn đề, chúng ta cần thêm các rào chắn vào hệ thống.
Rào chắn về cơ bản là một cổng kiểm soát chất lượng giữa những gì agent nói đã xong và nhiệm vụ thực sự được hoàn thành.
Có ba cách tiếp cận chính đối với rào chắn, và hầu hết các hệ thống production đều sử dụng ít nhất hai.
Đối với những thứ có tính xác định như định dạng và độ dài đầu ra, chúng ta chỉ cần sử dụng các đoạn code tiêu chuẩn. Chúng nhanh, rẻ và nên được ưu tiên khi có thể.
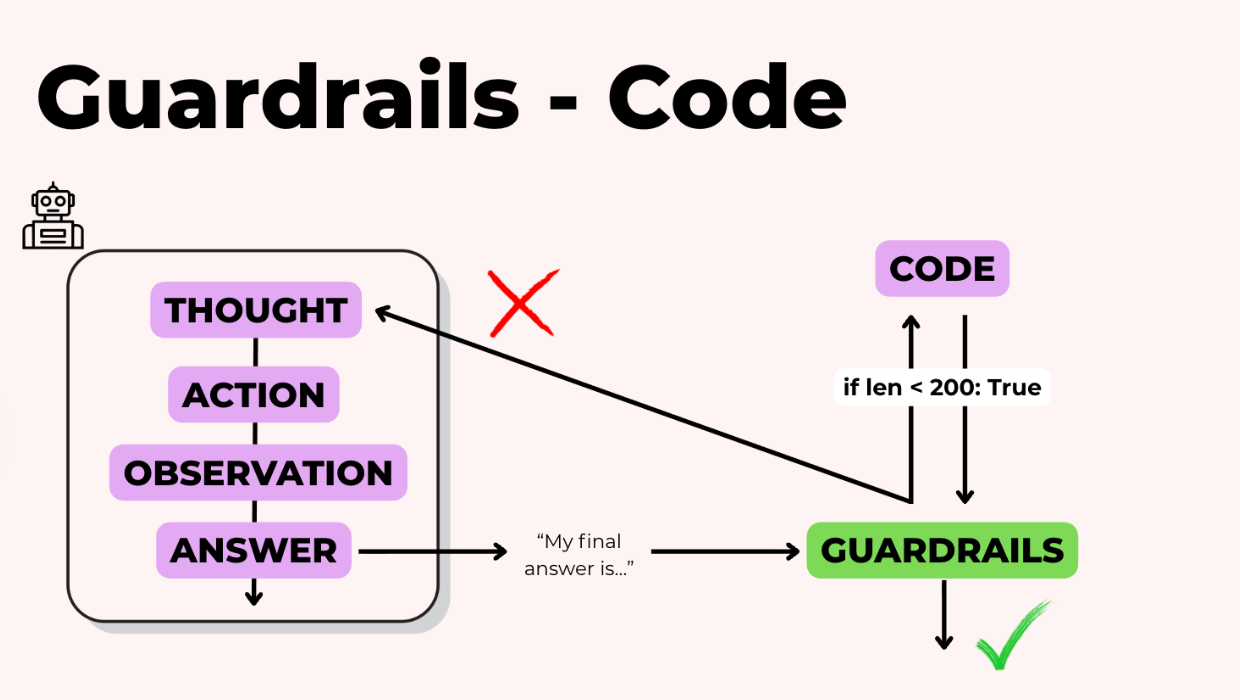
Đôi khi chúng ta kiểm tra những thứ tinh tế hơn như "Phản hồi này có nhất quán về mặt thực tế với các nguồn không?" hoặc "Giọng điệu có tích cực và chuyên nghiệp không?"
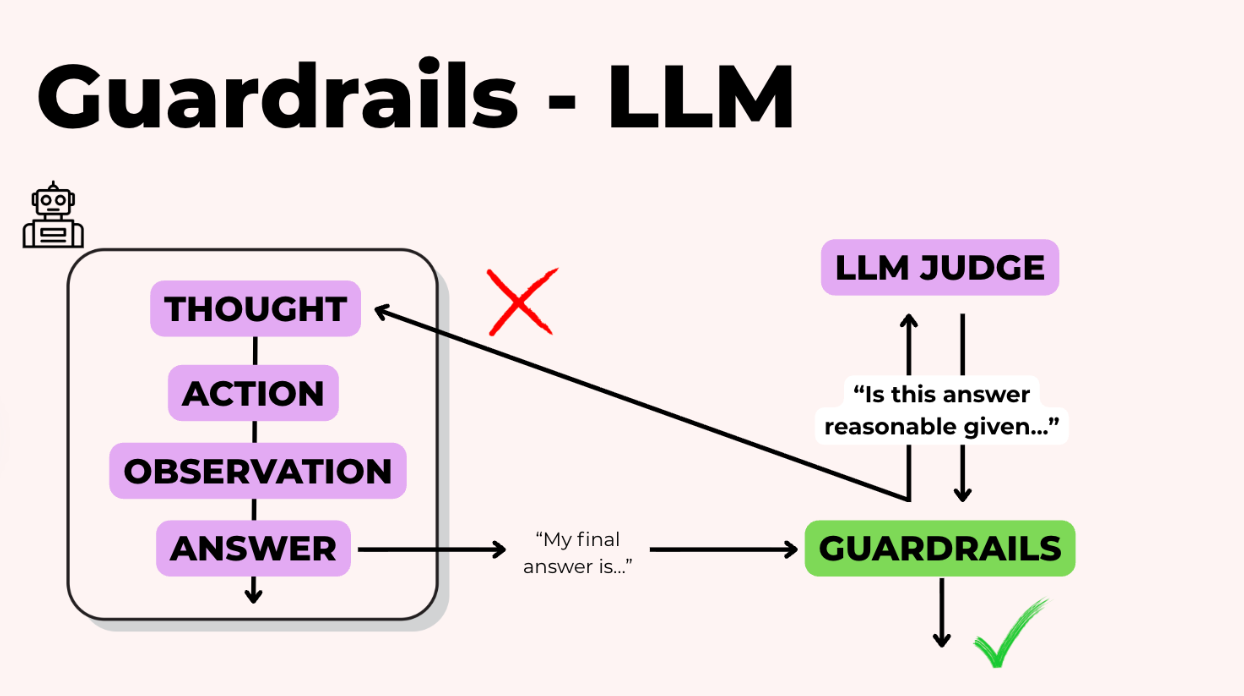
Trong trường hợp này, chúng ta có thể sử dụng một LLM khác để đánh giá đầu ra. Nếu LLM giám khảo nói "không, cái này không đạt," nó sẽ giải thích tại sao. Phản hồi đó được gửi lại cho agent của bạn, và agent sẽ sửa đổi và thử lại.
Cuối cùng, đôi khi bạn chỉ cần một con người để kiểm tra công việc.
Thay vì để agent hoàn thành và tự động gửi kết quả, bạn có thể yêu cầu nó dừng lại và xin phê duyệt trước. Bạn có thể đưa ra phản hồi và yêu cầu agent thử lại.
Các mẫu thiết kế (Design Patterns)
Được rồi, chúng ta đã đề cập rất nhiều về cách làm cho hệ thống hoạt động. Bây giờ hãy nói về cách làm cho hệ thống có chất lượng tốt hơn.
Có bốn mẫu cốt lõi giúp tăng chất lượng và khả năng một cách đáng tin cậy: suy ngẫm, sử dụng công cụ, lập kế hoạch và hợp tác đa agent.
Hãy bắt đầu với cái dễ nhất và hiệu quả nhất: Suy ngẫm (Reflection).
Suy ngẫm (Reflection)
Tóm lại, suy ngẫm về cơ bản chỉ có nghĩa là chúng ta không dừng lại ở bản nháp đầu tiên.
Khi bạn sử dụng suy ngẫm, mô hình tạo ra một cái gì đó, phê bình nó, sau đó viết lại nếu cần. Lượt thứ hai đó — được hướng dẫn bởi một prompt yêu cầu nó tìm và sửa các vấn đề — hầu như luôn làm cho mọi thứ tốt hơn.
Hãy để tôi cho bạn xem một ví dụ nhanh với một email.
Phiên bản 1 (bản nháp đầu tiên): "Chào, chúng ta hãy gặp nhau vào tháng tới để thảo luận về dự án. Cảm ơn".
Có gì sai với điều này? Ngày tháng mơ hồ ("tháng tới"), không có chữ ký, và "Cảm ơn" có vẻ đột ngột.
Bước suy ngẫm: Mô hình đọc v1 và phát hiện ra những vấn đề này — thời gian không rõ ràng, thiếu lời chào cuối thư, giọng điệu có vẻ vội vã.
Phiên bản 2 (đã sửa đổi): "Chào Alex, chúng ta hãy gặp nhau trong khoảng từ ngày 5–7 tháng 1 để thảo luận về tiến độ dự án. Hãy cho tôi biết thời gian nào phù hợp với bạn. Thân ái, Marina".
Nội dung này giống nhau nhưng sạch sẽ hơn, cụ thể hơn, chuyên nghiệp hơn.
Suy ngẫm trở nên thực sự mạnh mẽ với code vì bạn có thể thêm phản hồi từ bên ngoài. Bạn có thể viết code, để một agent phê bình xem xét nó, và sau đó thực sự chạy nó. Điều này cho phép bạn nắm bắt lỗi, kết quả kiểm thử và đầu ra, và đưa thông tin đó trở lại cho mô hình. Mô hình có thể sử dụng thông tin cụ thể đó để tạo ra một phiên bản v2 tốt hơn nhiều.
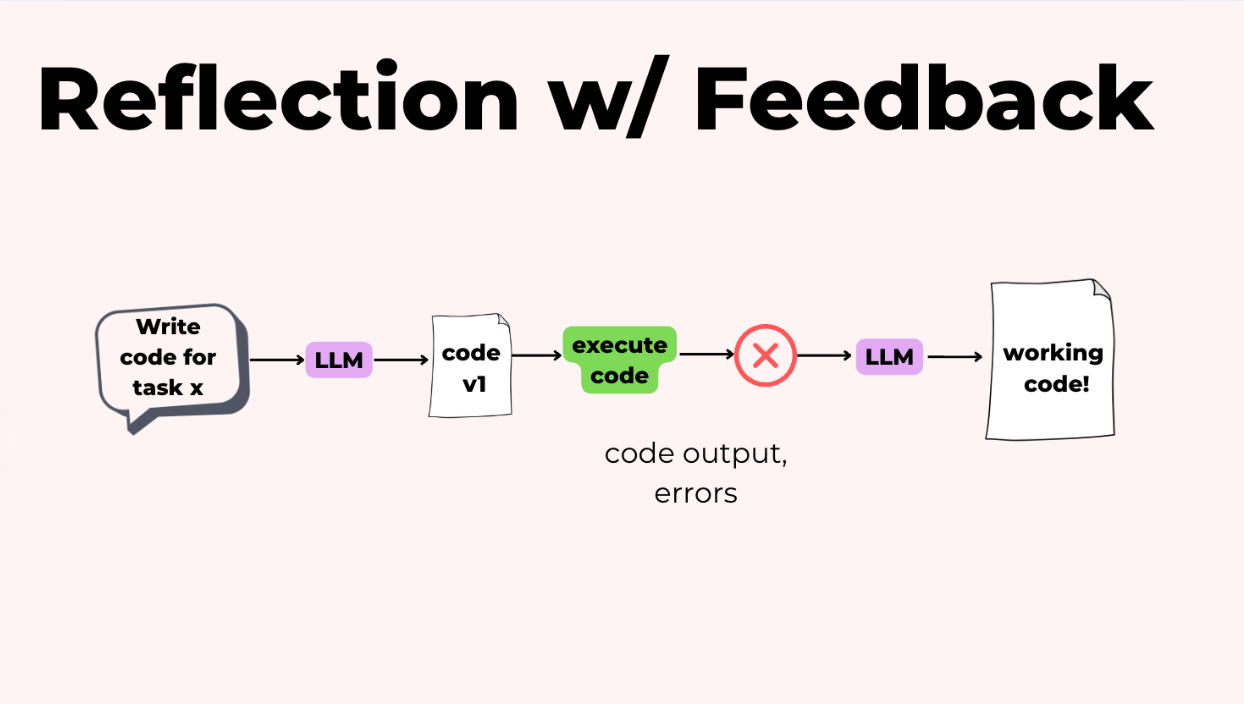
Suy ngẫm đặc biệt hữu ích khi bạn có các đầu ra có cấu trúc như JSON, các hướng dẫn theo quy trình như các bước pha trà nơi suy ngẫm có thể phát hiện các bước bị thiếu, công việc sáng tạo và viết lách dài.
Đặc biệt, suy ngẫm hoạt động tốt khi bạn có thể kết hợp phản hồi từ bên ngoài. Giống như chạy một trình xác thực schema trên JSON hoặc kiểm tra các trích dẫn bị thiếu trong một nhiệm vụ nghiên cứu.
Nhược điểm là nó làm tăng độ trễ và chi phí vì bạn đang thực hiện nhiều lượt. Vì vậy, hãy chắc chắn kiểm tra có và không có suy ngẫm để đảm bảo nó thực sự hữu ích.
Sử dụng công cụ (Tool Use)
Được rồi, hãy nói về mẫu thiết kế thứ hai: sử dụng công cụ.
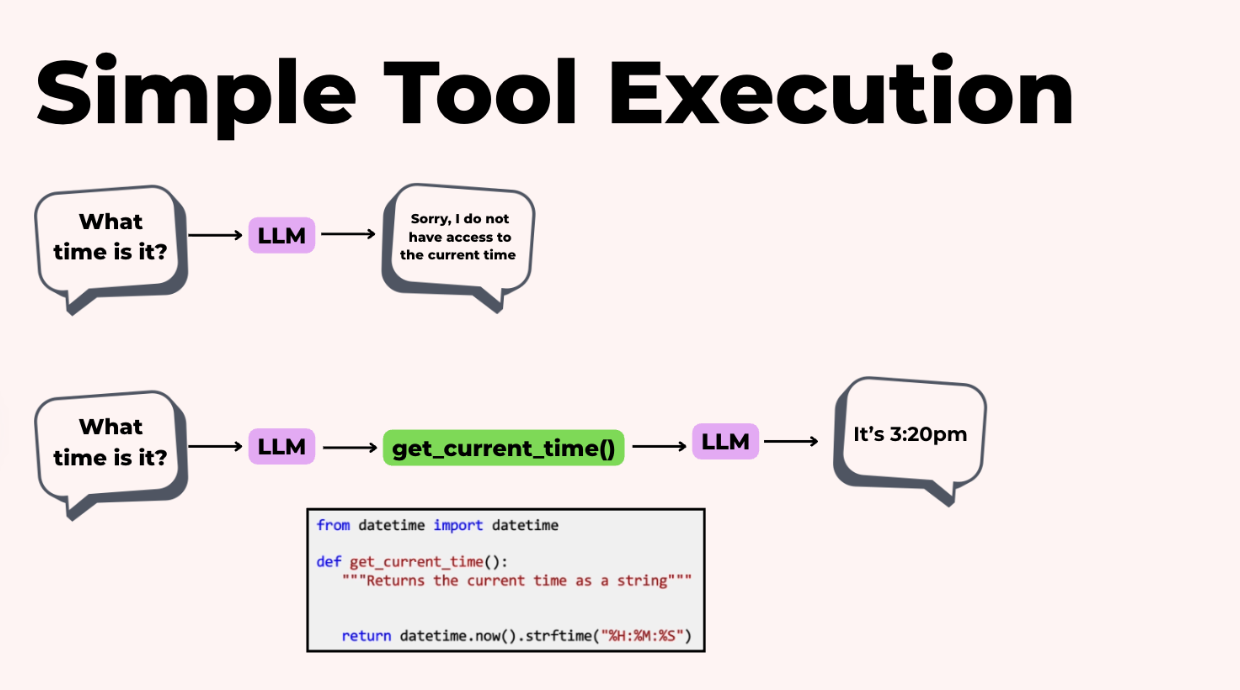
Đây là ý tưởng cốt lõi: bạn cung cấp cho LLM một menu các hàm mà nó có thể gọi. Đây có thể là những thứ như tìm kiếm web, truy vấn cơ sở dữ liệu, thực thi code, truy cập lịch, hoặc bất cứ thứ gì ứng dụng của bạn cần. Và sau đó mô hình quyết định khi nào và công cụ nào để sử dụng.
Điều này quan trọng vì một LLM tự nó chỉ là một trình tạo văn bản. Nó không biết bây giờ là mấy giờ hay bất cứ điều gì về dữ liệu bán hàng của công ty bạn. Nó không thể thực thi code để tính toán các câu trả lời chính xác.
Nhưng nếu bạn cung cấp cho nó các công cụ, nó có thể làm những việc như tìm kiếm trên web, truy vấn cơ sở dữ liệu, ghi vào CRM, hoặc chạy code.
Vì vậy, nếu tôi hỏi agent "Bây giờ là mấy giờ?" LLM sẽ gọi hàm getCurrentTime(), nhận lại "3:20 PM," và trả lời bằng thông tin đó.
Hoặc chúng ta có thể yêu cầu nó tìm kiếm các nhà hàng địa phương, truy vấn cơ sở dữ liệu, hoặc thực hiện một phép tính toán học. Trong mỗi trường hợp, mô hình nhận ra nó cần thông tin hoặc tính toán từ bên ngoài, chọn đúng công cụ, và sử dụng kết quả để trả lời.
Khi bạn cung cấp cho mô hình nhiều công cụ, nó có thể xâu chuỗi chúng lại với nhau. Ví dụ, giả sử bạn đang xây dựng một trợ lý lịch. Bạn đã cung cấp ba công cụ: checkCalendar, makeAppointment, và deleteAppointment.
Người dùng hỏi: "Lên lịch một cuộc họp với Alice trong tuần này."
Mô hình suy nghĩ qua các bước:
- Đầu tiên, tôi cần kiểm tra lịch của Alice để xem cô ấy rảnh khi nào.
checkCalendar(name='Alice') - Lịch của Alice cho thấy cô ấy rảnh vào thứ Ba lúc 2 giờ chiều.
- Bây giờ tôi có thể đặt cuộc hẹn.
makeAppointment(name='Alice', time='Tuesday 2 PM') - Cuộc hẹn đã được xác nhận.
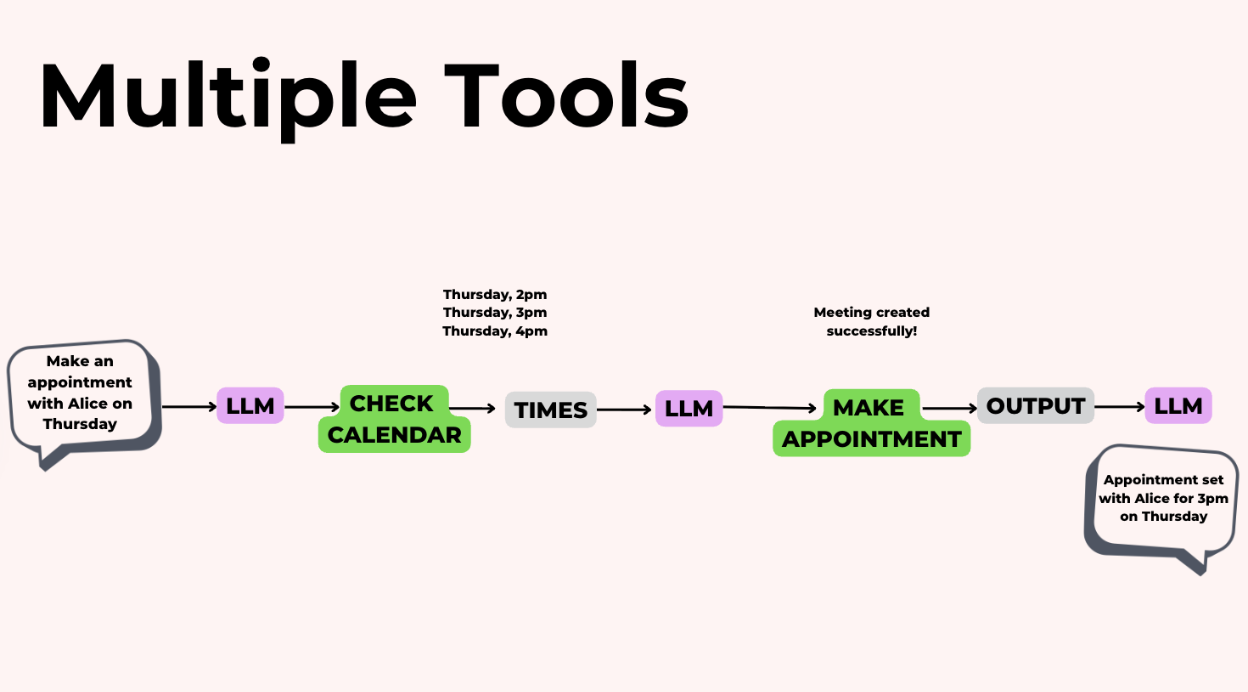
Điều quan trọng ở đây là LLM đang chọn công cụ nào để gọi tiếp theo dựa trên những gì nó học được từ đầu ra của công cụ trước đó. Nó không phải là một quy trình cố định — nó là động.
Được rồi, nhưng vấn đề là: LLM chỉ tạo ra văn bản. Chúng không thực thi code. Vậy làm thế nào chúng "gọi" một hàm?
Thực ra chúng không gọi. Chúng yêu cầu một lệnh gọi hàm.
Đây là vòng lặp bên trong:
- Người dùng đưa ra một prompt.
- LLM nhận prompt và danh sách các công cụ có sẵn.
- LLM tạo ra một văn bản đặc biệt yêu cầu gọi một công cụ (ví dụ: một JSON có tên hàm và các tham số).
- Ứng dụng của bạn phân tích văn bản đó.
- Ứng dụng của bạn thực thi hàm được yêu cầu.
- Ứng dụng của bạn lấy kết quả, đưa nó trở lại LLM, và LLM sử dụng nó để tạo ra câu trả lời cuối cùng.
Nó đơn giản như vậy. LLM yêu cầu nhưng không thực sự thực thi code.
Thiết kế công cụ tốt
Để LLM có thể tìm và yêu cầu các công cụ, chúng ta cần một cách nhất quán để định nghĩa chúng. Mỗi công cụ có hai phần:
- Một giao diện (interface) với tên, mô tả và các tham số đầu vào.
Ví dụ: "ReadWebsiteContent" với mô tả "Lấy và trả về nội dung văn bản của một trang web" và một đầu vào: url (string).
- Và mã triển khai (implementation code). Bất cứ thứ gì bạn cần như truy vấn SQL, xác thực, thử lại, điều tiết, và phân tích cú pháp.
Agent chỉ nhìn thấy giao diện. Tất cả các chi tiết triển khai lộn xộn đều được ẩn đi.
Các công cụ tốt cũng xem xét những thứ như xử lý lỗi, tự phục hồi và giới hạn tốc độ. Chúng có thể sử dụng bộ nhớ đệm (caching) để ghi nhớ kết quả cho các đầu vào giống hệt nhau để giảm độ trễ, chi phí và tải API bên ngoài. Và chúng nên có hỗ trợ bất đồng bộ (async) để agent (hoặc các agent khác) có thể tiếp tục làm việc trong khi một yêu cầu công cụ dài đang hoàn thành.
Các công cụ nên được xây dựng như các sản phẩm với phiên bản, tài liệu phù hợp và đủ các bài kiểm thử. Rất hữu ích khi duy trì một sổ đăng ký nội bộ các công cụ đã được kiểm duyệt với tài liệu, phiên bản và quyền sở hữu.
Kết hợp tất cả những điều đó lại, và bây giờ bạn đã cung cấp cho agent của mình một cách để tương tác với thế giới. Điều đó thật tuyệt! Nhưng chúng ta cần đảm bảo rằng agent biết nó cần làm gì trong thế giới thực, điều này dẫn chúng ta đến mẫu thiết kế thứ ba: lập kế hoạch.
Lập kế hoạch (Planning)
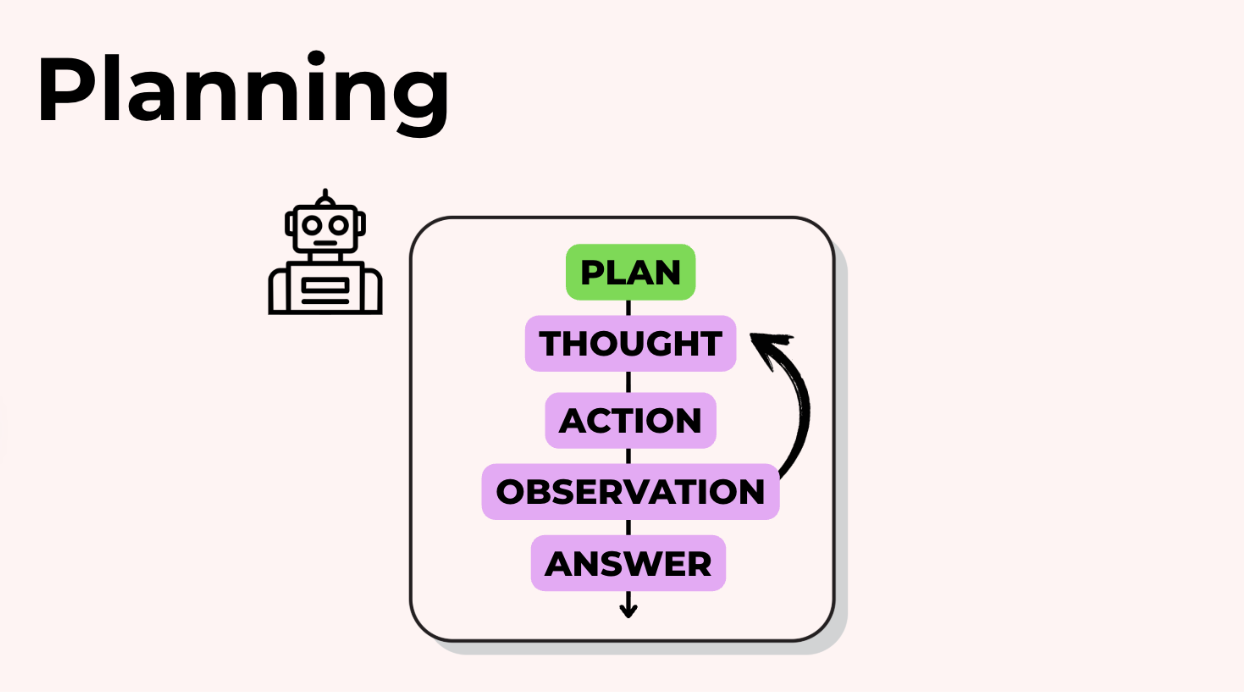
Đây là ý tưởng với việc lập kế hoạch: thay vì mã hóa cứng một chuỗi các bước cố định, bạn để LLM quyết định phải làm gì và theo thứ tự nào.
Giả sử bạn đang xây dựng một agent dịch vụ khách hàng cho một cửa hàng bán lẻ. Bạn có thể mã hóa cứng các luồng cho mọi tình huống: "Nếu đó là câu hỏi về giá, hãy làm X. Nếu đó là trả hàng, hãy làm Y. Nếu đó là hàng tồn kho, hãy làm Z."
Nhưng điều gì sẽ xảy ra khi ai đó hỏi một điều gì đó bạn không lường trước được? Hoặc khi cùng một câu hỏi cần các bước khác nhau tùy thuộc vào ngữ cảnh?
Với việc lập kế hoạch, bạn cung cấp cho agent một bộ công cụ gồm các hàm như get_item_descriptions, check_inventory, get_item_price, process_return và để nó tự tìm ra công cụ nào để sử dụng và khi nào.
Vòng lặp cơ bản trông như thế này:
- Người dùng đưa ra một yêu cầu.
- LLM tạo ra một kế hoạch gồm nhiều bước.
- LLM thực hiện bước đầu tiên của kế hoạch (thường là gọi một công cụ).
- Nó quan sát kết quả và cập nhật kế hoạch của mình nếu cần, sau đó tiếp tục.
Về cơ bản nó là "lập kế hoạch → hành động → quan sát → tiếp tục," nhưng với các công cụ của bạn.
Một ví dụ cụ thể: Kính râm bán lẻ
Người dùng hỏi: "Có kính râm gọng tròn nào trong kho dưới 100 đô la không?"
Agent có thể lập kế hoạch:
Bước 1: Sử dụng get_item_descriptions để tìm gọng tròn
Bước 2: Chạy check_inventory trên danh sách đó
Bước 3: Gọi get_item_price trên các mặt hàng còn trong kho và lọc dưới 100 đô la
Bước 4: Soạn câu trả lời
Bạn không định nghĩa trước công thức chính xác này. LLM đã chọn nó từ các công cụ có sẵn.
Bây giờ một câu hỏi khác xuất hiện: "Tôi muốn trả lại chiếc kính râm gọng vàng tôi đã mua, không phải chiếc gọng kim loại."
Kế hoạch thay đổi hoàn toàn trong trường hợp này:
Bước 1: Xác định các giao dịch mua trước đây của người dùng
Bước 2: Khớp với sản phẩm gọng vàng
Bước 3: Gọi process_item_return
Bước 4: Xác nhận kết quả
Sẽ rất hữu ích nếu yêu cầu mô hình xuất ra một kế hoạch có cấu trúc dưới dạng JSON.

Hoặc, bạn có thể để nó viết code thực tế, thường là Python, mã hóa toàn bộ kế hoạch.

Những điều cần chú ý với việc lập kế hoạch
Lập kế hoạch làm tăng tính tự chủ, điều đó cũng có nghĩa là nó làm tăng tính khó đoán. Bạn cần có các rào chắn về những thứ như quyền hạn, xác thực các lệnh gọi công cụ và quản lý việc chuyển đầu ra của một bước sang bước tiếp theo.
Ngày nay, trường hợp sử dụng mạnh nhất cho việc lập kế hoạch là các hệ thống lập trình có tính tác tử cao. Mô hình chia nhỏ một nhiệm vụ lập trình thành các bước và thực hiện nó.
Đối với các lĩnh vực khác, việc lập kế hoạch hoàn toàn hoạt động, nhưng khó kiểm soát hơn vì bạn không biết trước kế hoạch mà mô hình sẽ tạo ra. Tuy nhiên, các công cụ và rào chắn đang được cải thiện nhanh chóng, và việc áp dụng đang ngày càng tăng.
Nhưng nếu bạn có một hệ thống mà bạn cần làm nhiều việc khác nhau, có thể là đồng thời? Đó là lúc sự hợp tác đa agent phát huy tác dụng.
Đa agent (Multi-Agent)
Hãy nghĩ về cách bạn sẽ giải quyết một dự án phức tạp trong đời thực. Bạn không thuê một người siêu đa năng để làm mọi thứ. Bạn xây dựng một đội. Bạn có các chuyên gia thực sự giỏi trong lĩnh vực cụ thể của họ, và họ chuyển giao công việc cho nhau.
Các hệ thống đa agent mượn tư duy tương tự.
Mỗi agent có một vai trò rõ ràng. Mỗi agent tập trung vào những gì nó giỏi. Đầu ra tốt hơn vì bạn có sự chuyên môn hóa ở mỗi bước.
Ngoài sự chuyên môn hóa, còn có một số lợi thế khác của hệ thống đa agent:
- Nó tránh việc bất kỳ agent nào có cửa sổ ngữ cảnh (context window) quá lớn.
- Bạn có thể sử dụng nhiều LLM. Bạn có thể kết hợp các mô hình nhanh hơn, rẻ hơn cho các tác vụ đơn giản số lượng lớn và dành các mô hình lớn hơn, có năng lực hơn cho các tác vụ chính xác như chiến lược, trả lời khách hàng tinh tế, hoặc viết lách dài. Điều này mang lại cho bạn sự linh hoạt về cả chi phí và hiệu suất.
- Bạn có thể song song hóa công việc.
- Và nếu bạn có các hoạt động chạy rất lâu, bạn có thể chia nhỏ công việc và xem agent nào đang làm gì để giúp người dùng hiểu điều gì đang xảy ra.
Nếu bạn có một nhiệm vụ đơn giản, hãy bỏ qua hệ thống đa agent. Chúng có thể làm chậm mọi thứ và khiến việc gỡ lỗi trở nên khó khăn hơn.
Điều này là do các hệ thống đa agent giới thiệu một lớp phức tạp hoàn toàn mới. Bạn có thể gặp xung đột tài nguyên nếu hai agent cố gắng sửa đổi cùng một tệp, có chi phí giao tiếp giữa các agent và các phụ thuộc nhiệm vụ phức tạp. Cũng có những vấn đề như giới hạn tốc độ API, và phải làm gì nếu một agent thất bại — các agent khác có tiếp tục không hay bạn phải quay lại? Và làm thế nào để bạn kết hợp những gì nhiều agent đã tạo ra thành một đầu ra mạch lạc?
Điều này không phải là không thể quản lý, nhưng bạn cần thiết kế cho nó. Bạn cần sự điều phối mạnh mẽ, xử lý lỗi tốt và các giao thức rõ ràng về cách các agent giao tiếp.
Thiết kế hệ thống đa agent
Vậy hãy nói thêm về cách thiết kế các hệ thống đa agent này. Hãy sử dụng ví dụ về việc tạo một brochure marketing để minh họa các lựa chọn của chúng ta.
Mô hình vai trò (The Roles Model)
Bước đầu tiên là xác định các agent của bạn theo vai trò. Mỗi agent được giao một mô tả công việc rõ ràng và chỉ những công cụ cần thiết để thực hiện công việc đó.
Đối với brochure marketing của chúng ta, bạn có thể có:
Một agent nghiên cứu tìm kiếm xu hướng thị trường và động thái của đối thủ cạnh tranh. Agent này có thể có các công cụ để tìm kiếm trên web, truy xuất thông tin và có thể là ghi chú.
Một agent thiết kế đồ họa tạo biểu đồ và tài sản hình ảnh với các công cụ để tạo hình ảnh, thao tác hình ảnh hoặc thực thi code để vẽ biểu đồ.
Và một agent viết lách biến các phát hiện và tài sản thành bản sao cuối cùng. Agent này có thể chỉ là chính LLM mà không cần công cụ bên ngoài.
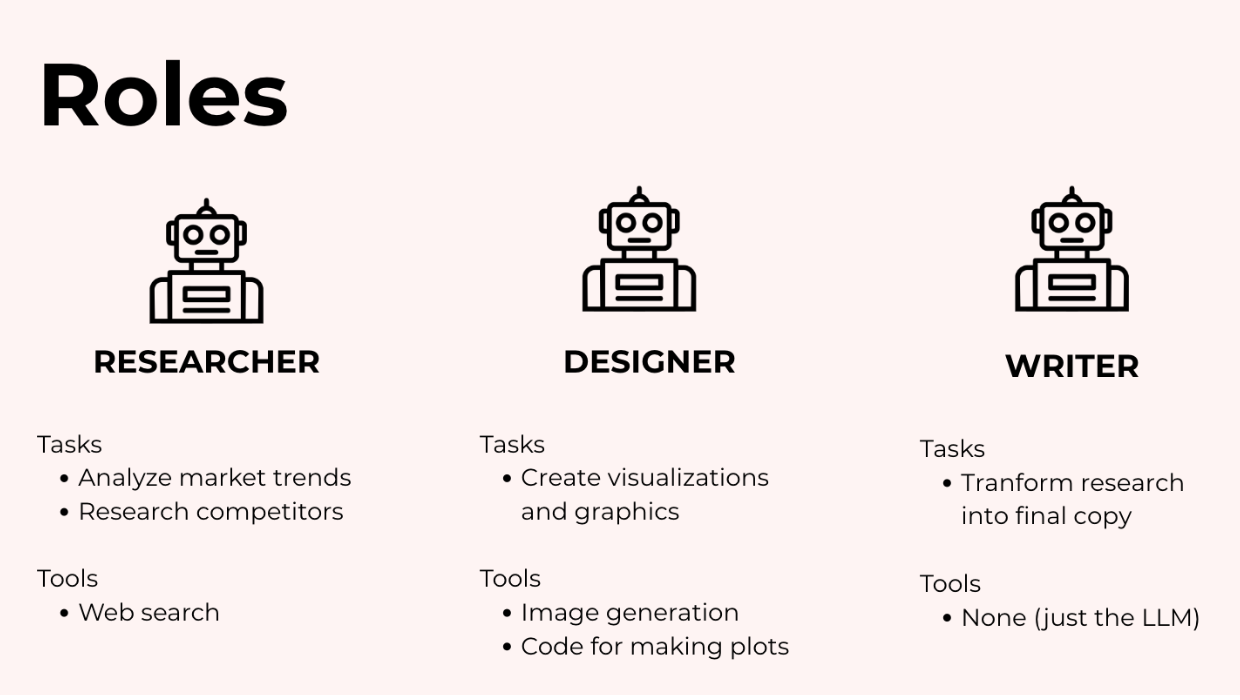
Bạn triển khai mỗi agent bằng cách đưa ra một vai trò, như "bạn là một agent nghiên cứu chuyên về phân tích thị trường" và chỉ cung cấp cho nó những công cụ mà vai trò đó nên có.
Khi bạn đã xác định các agent của mình, bạn cần quyết định cách chúng giao tiếp. Có bốn mẫu chính mà chúng ta sẽ thảo luận, từ đơn giản nhất đến phức tạp nhất.
Mẫu 1: Tuần tự (Sequential)
Đây là cách đơn giản và dễ dự đoán nhất. Mỗi agent hoàn thành công việc của mình, sau đó chuyển đầu ra cho agent tiếp theo trong hàng.
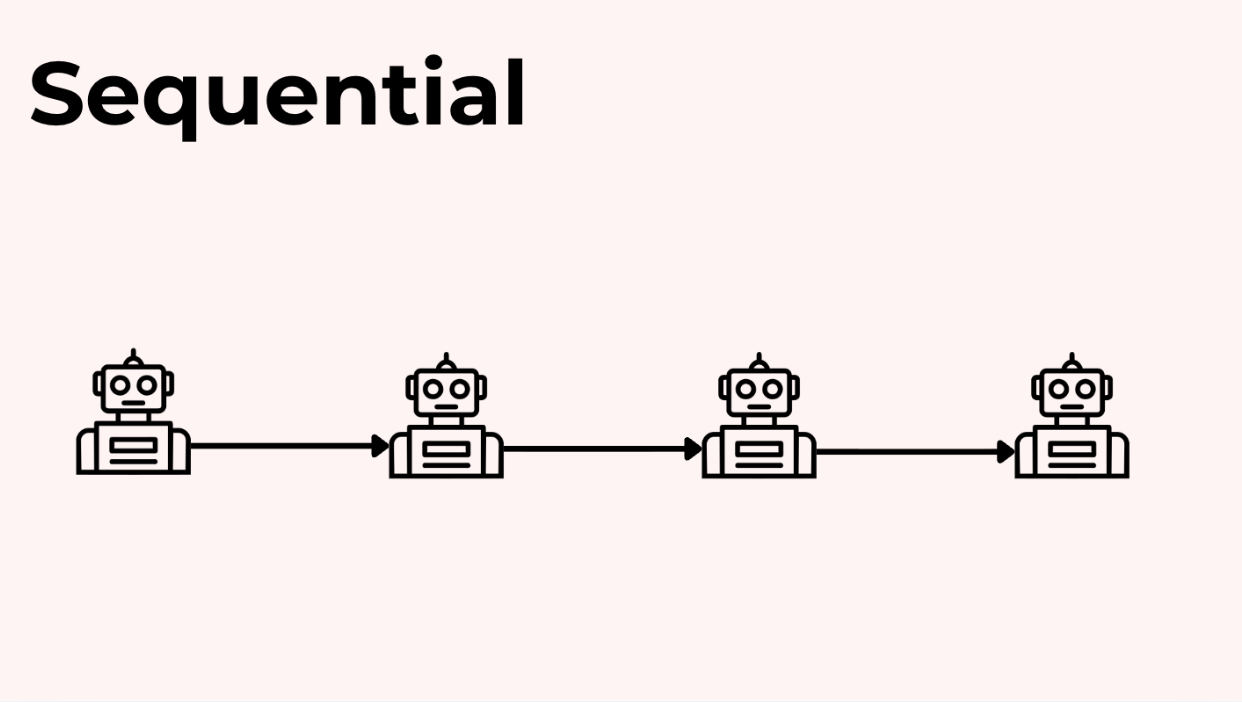
Đối với brochure của chúng ta, nó có thể trông như thế này: Agent nghiên cứu hoàn thành → chuyển cho Agent thiết kế → Agent thiết kế hoàn thành → chuyển cho Agent viết lách → xong.
Nó giống như một dây chuyền lắp ráp. Dễ gỡ lỗi và có thời gian và chi phí có thể dự đoán được.
Đây là nơi bạn nên bắt đầu. Tùy thuộc vào trường hợp sử dụng của bạn, điều này có thể là đủ.
Mẫu 2: Song song (Parallel)
Nhưng tuần tự không phải là lựa chọn duy nhất. Bạn cũng có thể chạy các agent song song khi các bước không phụ thuộc vào nhau, điều này rất tốt để giảm độ trễ.
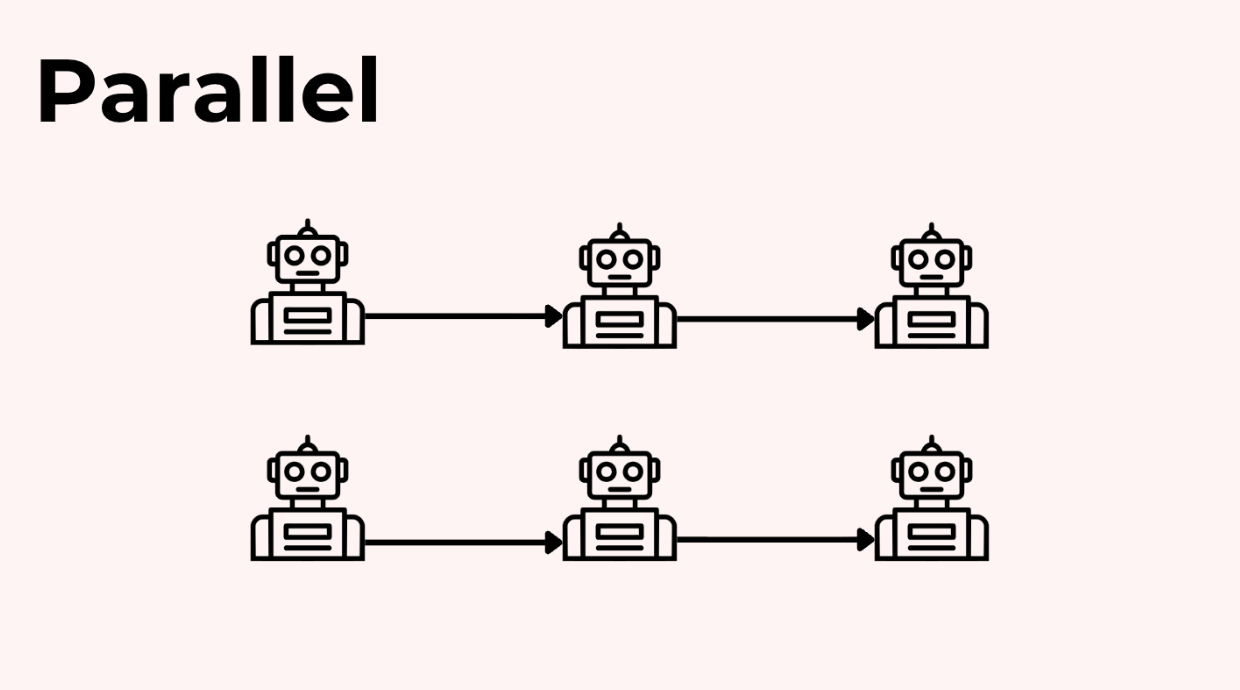
Ví dụ, Agent nghiên cứu và Agent thiết kế của bạn có thể làm việc đồng thời trên các phần độc lập của brochure, sau đó Agent viết lách kết hợp các đầu ra của họ.
Điều này tăng tốc mọi thứ nhưng làm tăng độ phức tạp trong việc điều phối.
Mẫu 3: Phân cấp một quản lý (Single Manager Hierarchy)
Nếu bạn bắt đầu đi vào các quy trình làm việc phức tạp hơn, việc thêm một agent quản lý để lập kế hoạch và điều phối có thể hữu ích. Các agent chuyên gia thực hiện công việc của họ và báo cáo lại cho người quản lý, chứ không phải cho nhau.
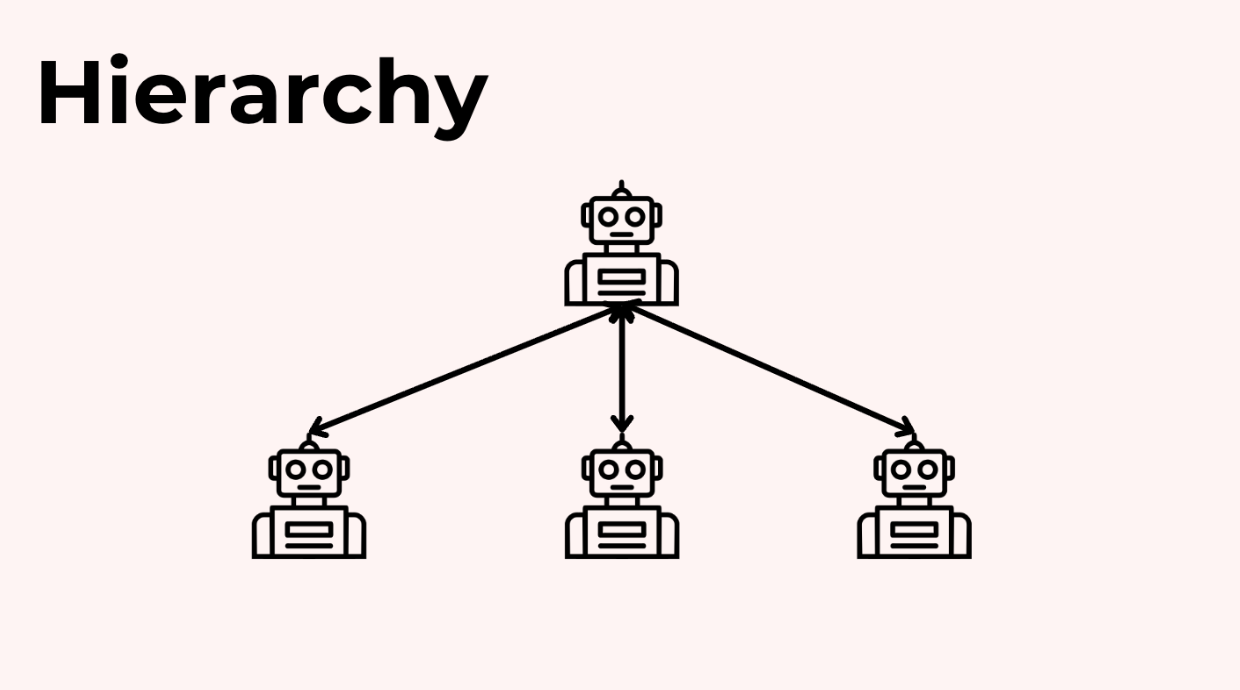
Điều này giữ cho việc kiểm soát chặt chẽ trong khi vẫn cho bạn sự linh hoạt. Người quản lý có thể sắp xếp lại các bước, bỏ qua những thứ không cần thiết, hoặc yêu cầu các agent làm lại công việc. Nó dễ thích ứng hơn một luồng tuyến tính mà không bị hỗn loạn.
Đây có lẽ là mẫu phổ biến nhất trong các hệ thống đa agent production hiện nay.
Đối với các quy trình làm việc phức tạp hơn nữa, bạn có thể có các hệ thống phân cấp sâu hơn, nơi một số agent quản lý các agent con của riêng chúng.
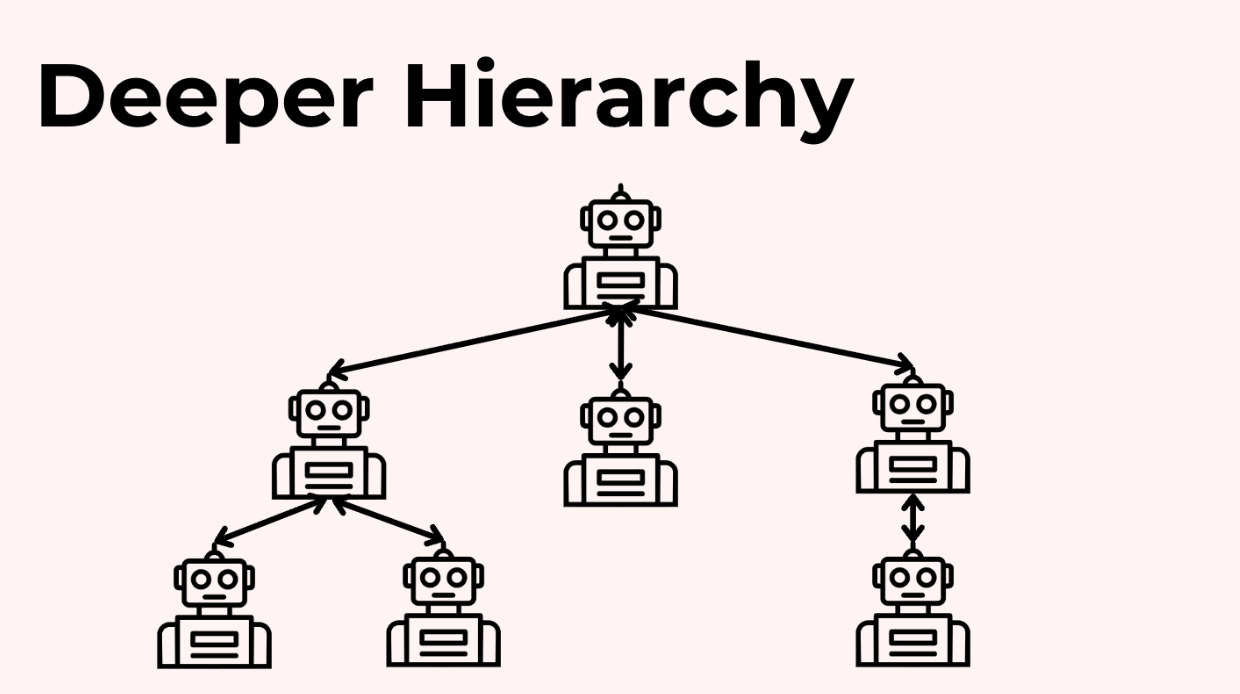
Ví dụ, agent Nghiên cứu của bạn có thể điều phối một agent con Nghiên cứu-Web và một agent con Kiểm-tra-Sự-thật. Agent Viết lách của bạn có thể có một agent Viết-theo-Phong-cách và một agent Kiểm-tra-Trích-dẫn làm việc dưới quyền nó. Điều này hữu ích cho các nhiệm vụ rất phức tạp nhưng tất nhiên cũng thêm một chút hỗn loạn.
Mẫu 4: Tất cả-đến-Tất cả (Trò chuyện tự do)
Cuối cùng, chúng ta có mô hình tất cả-đến-tất cả, có thể RẤT hỗn loạn. Trong mô hình này, bất kỳ agent nào cũng có thể nhắn tin cho bất kỳ agent nào khác vào bất kỳ lúc nào. Điều này hiếm khi xảy ra trong production vì khó dự đoán và kiểm soát. Đầu ra có thể thay đổi rất nhiều từ lần chạy này sang lần chạy khác.
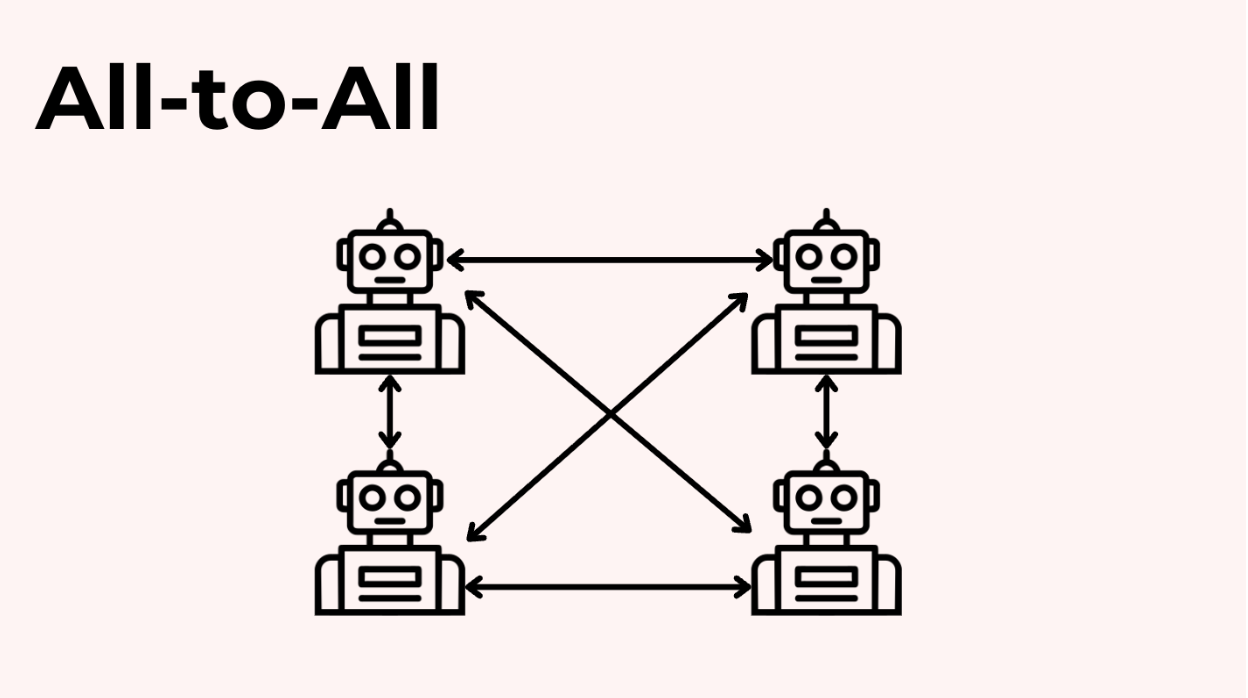
Nhưng nó có thể hoạt động cho các nhiệm vụ mang tính động não, sáng tạo hoặc có rủi ro thấp hơn. Giống như tạo ra nhiều biến thể của bản sao quảng cáo, nơi nếu một lần chạy tạo ra rác, bạn chỉ cần thử lại.
Những cạm bẫy trong điều phối
Chúng ta đã nói về những thách thức với việc điều phối một vài lần. Dưới đây là hai trong số những cạm bẫy phổ biến nhất.
Đầu tiên, công việc dư thừa. Nhiều agent có thể thực hiện lại cùng một tìm kiếm hoặc gọi cùng một công cụ. Điều này có thể được giải quyết bằng cách thắt chặt phạm vi nhiệm vụ và có sự phân công lao động rõ ràng giữa các agent.
Thứ hai, tuần tự hóa không cần thiết. Việc xâu chuỗi các bước có thể chạy đồng thời làm chậm mọi thứ. Để giải quyết vấn đề này, hãy xác định các nhiệm vụ thực sự độc lập và chạy chúng một cách bất đồng bộ, sau đó chỉ định tuyến các phần ngữ cảnh mà bước tiếp theo cần.
Nói chung, bạn sẽ muốn bắt đầu với phương pháp điều phối đơn giản nhất có thể và chỉ thêm độ phức tạp khi cần thiết.
Các phương pháp hay nhất (Best Practices)
Bất kể bạn chọn mẫu nào, đây là bốn phương pháp hay nhất cần ghi nhớ khi thiết kế hệ thống của bạn:
1. Định nghĩa giao diện rõ ràng, đừng chỉ dựa vào cảm tính.
Mỗi agent cần một schema rõ ràng cho đầu vào và đầu ra. Nó cần biết những thứ như: Trường nào? Loại nào? ID hoặc tham chiếu nào được chuyển tiếp?
Việc chuyển giao thường bị hỏng nhiều hơn là các mô hình. Nếu agent Nghiên cứu của bạn trả về một khối dữ liệu không có cấu trúc và agent Thiết kế của bạn không biết cách phân tích nó, toàn bộ hệ thống sẽ thất bại.
2. Phân định phạm vi công cụ cho mỗi agent.
Chỉ cung cấp cho mỗi agent những công cụ mà nó thực sự cần. Nguyên tắc đặc quyền tối thiểu.
Điều này giúp về mặt bảo mật và làm cho hệ thống dễ suy luận, dễ kiểm toán và dễ gỡ lỗi hơn.
3. Ghi lại dấu vết (trace).
Lưu giữ các tạo tác (artifact) của mỗi bước. Mỗi agent đã lên kế hoạch gì? Nó đã sử dụng những prompt nào? Nó đã thực hiện những lệnh gọi công cụ nào? Kết quả trả về là gì?
Khi có sự cố, dấu vết này giúp phân tích lỗi nhanh chóng. Bạn có thể thấy chính xác mọi thứ đã sai ở đâu.
4. Đánh giá các thành phần VÀ từ đầu đến cuối
Bạn cần hai loại đánh giá:
Cấp độ thành phần: Nghiên cứu có liên quan không? Hình ảnh có chất lượng cao không? Giọng điệu của bản sao có phù hợp không?
Và từ đầu đến cuối: Brochure cuối cùng có tốt không? Nó có đáp ứng các yêu cầu không?
Nếu đánh giá từ đầu đến cuối của bạn cho thấy vấn đề nhưng tất cả các đánh giá thành phần của bạn đều ổn, bạn biết đó là vấn đề chuyển giao hoặc tích hợp. Nếu một đánh giá thành phần cụ thể thất bại, bạn biết agent nào cần cải thiện.
NÂNG CAO
Được rồi, chào mừng đến với phần nâng cao. Nếu bạn đã đi được đến đây, bạn đang nghiêm túc về việc xây dựng các hệ thống agent thực sự có thể hoạt động trong thế giới thực.
Các kỹ thuật đã giúp bạn từ con số không đến nguyên mẫu sẽ không đưa bạn từ nguyên mẫu đến production. Bạn cần các công cụ khác, tư duy khác và kỷ luật hơn.
Hãy đi vào những điều đó ngay bây giờ.
Phân rã nhiệm vụ nâng cao cho hệ thống đa agent
Chúng ta đã nói về việc phân rã nhiệm vụ. Nhưng điều này ngày càng trở nên phức tạp khi bạn làm việc với các hệ thống đa agent.
Có bốn mẫu chính bạn có thể sử dụng để hướng dẫn bạn làm tốt điều này. Nhân tiện, tôi đã điều chỉnh điều này từ bài blog tuyệt vời này — hãy xem nó để biết thêm chi tiết!)
Mẫu 1: Phân rã theo chức năng (Functional Decomposition)
Trong mẫu này, chúng ta chia các nhiệm vụ theo lĩnh vực kỹ thuật hoặc chuyên môn. Đây là những gì chúng ta đã sử dụng trong các ví dụ của mình cho đến nay — chia nhỏ các nhiệm vụ theo loại công việc cần được thực hiện.
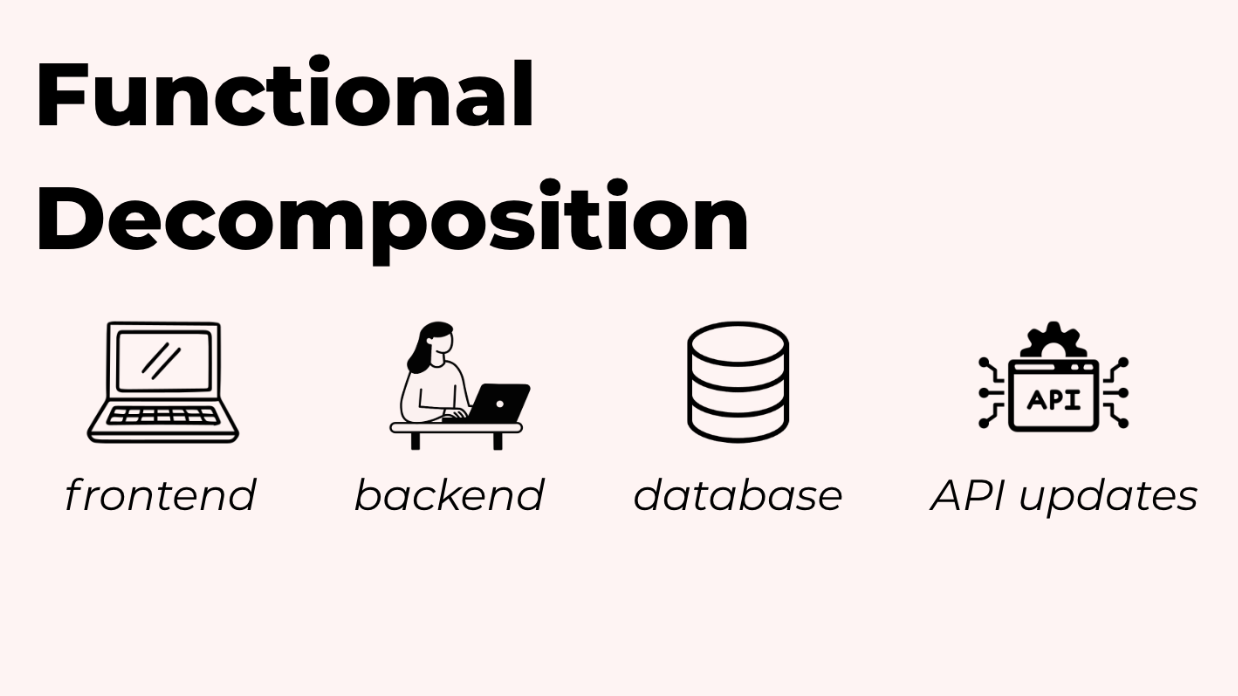
Ví dụ, bạn có thể nghĩ về việc phát triển tính năng full-stack. Bạn có công việc frontend, logic backend, thay đổi cơ sở dữ liệu và có thể là cập nhật API. Mỗi thứ này đòi hỏi kiến thức và công cụ khác nhau. Vì vậy, bạn tạo ra các agent chuyên về từng lĩnh vực.
Mẫu 2: Phân rã theo không gian (Spatial Decomposition)
Bạn cũng có thể chia theo cấu trúc tệp hoặc thư mục. Điều này đặc biệt mạnh mẽ khi bạn làm việc với các codebase lớn có nhiều tệp có thể được xử lý độc lập.
Giả sử bạn đang thực hiện một cuộc tái cấu trúc quy mô lớn — có thể là cập nhật tất cả các điểm cuối API của bạn sang một hệ thống xác thực mới, và bạn có hàng tá tệp trên các dịch vụ khác nhau.
Bạn phân rã theo không gian:
- Agent 1 xử lý /services/users/*
- Agent 2 xử lý /services/orders/*
- Agent 3 xử lý /services/payments/*
- Agent 4 xử lý /services/notifications/*
Trong trường hợp này, bạn giảm thiểu xung đột bằng cách đảm bảo các agent làm việc trên các phần riêng biệt của codebase. Chúng có thể làm việc song song. Nhưng nếu các tệp của bạn có các phụ thuộc phức tạp lẫn nhau, việc phân rã theo không gian sẽ không còn hiệu quả.
Mẫu 3: Phân rã theo thời gian (Temporal Decomposition)
Mẫu 3 là về việc chia các nhiệm vụ thành các giai đoạn tuần tự, trong đó các giai đoạn sau phụ thuộc vào việc hoàn thành các giai đoạn trước.
Hãy sử dụng việc ra mắt sản phẩm làm ví dụ. Bạn không thể chỉ thức dậy vào một ngày và bắt đầu gửi email quảng cáo. Có một trình tự logic:
Giai đoạn 1: Nghiên cứu thị trường — Phân tích đối thủ cạnh tranh, khảo sát khách hàng mục tiêu, xác định cơ hội định vị Giai đoạn 2: Lập kế hoạch ra mắt — Xác định thông điệp, đặt giá, tạo dòng thời gian, xác định các kênh Giai đoạn 3: Tạo tài sản — Viết bản sao, thiết kế đồ họa, xây dựng trang đích, chuẩn bị chuỗi email Giai đoạn 4: Ra mắt & Giám sát — Thực hiện chiến dịch, theo dõi chỉ số, phản hồi lại, điều chỉnh trong thời gian thực
Mỗi giai đoạn có agent hoặc nhóm agent riêng. Giai đoạn 2 không bắt đầu cho đến khi Giai đoạn 1 hoàn thành và được xem xét.
Mẫu 4: Phân rã theo dữ liệu (Data-Driven Decomposition)
Và cuối cùng, chúng ta có thể chia theo các phân vùng dữ liệu. Mẫu này ít phổ biến hơn nhưng thực sự mạnh mẽ cho một số trường hợp sử dụng nhất định, đặc biệt là các nhiệm vụ liên quan đến các tập dữ liệu lớn nơi bạn có thể phân vùng dữ liệu và xử lý các khối một cách độc lập.
Giả sử bạn đang phân tích nhật ký ứng dụng để xác định các vấn đề về hiệu suất. Bạn có gigabyte nhật ký từ tháng trước.
Bạn phân vùng theo thời gian hoặc theo dịch vụ:
- Agent 1 xử lý nhật ký Tuần 1
- Agent 2 xử lý nhật ký Tuần 2
- Agent 3 xử lý nhật ký Tuần 3
- Agent 4 xử lý nhật ký Tuần 4
Mỗi agent chạy phân tích một cách độc lập, sau đó bạn tổng hợp kết quả ở cuối.
Bạn cũng có thể kết hợp các mẫu này. Ví dụ, một tính năng full-stack có thể sử dụng phân rã theo chức năng cho cấu trúc chính (frontend, backend, cơ sở dữ liệu), nhưng agent backend lại sử dụng phân rã theo thời gian bên trong (thiết kế API → triển khai logic → thêm kiểm thử).
Cải thiện chất lượng
Được rồi, tại thời điểm này, giả sử chúng ta có một hệ thống đang hoạt động, chúng ta đã thực hiện một đánh giá toàn diện để tìm lỗi, và chúng ta vẫn không hài lòng với hiệu suất. Đây là những gì cần làm.
Điều đầu tiên cần hiểu là bạn đang làm việc với hai loại thành phần hoàn toàn khác nhau, và chúng cần các chiến lược cải thiện khác nhau.
Đầu tiên chúng ta có các thành phần không phải LLM. Đây là những thứ như tìm kiếm web, truy xuất RAG, thực thi code, nhận dạng giọng nói, mô hình thị giác, trình phân tích PDF.
Những thứ này có thể được cải thiện theo hai cách chính:
- Tinh chỉnh các thông số. Vọc vạch những thứ như phạm vi ngày tìm kiếm trên web, top-k kết quả, kích thước chunk RAG, ngưỡng tương đồng, v.v.
- Hoặc, đổi nhà cung cấp. Thử các API tìm kiếm web thay thế. Các mô hình OCR hoặc thị giác khác nhau, v.v.
Sau đó, chúng ta có các thành phần LLM. Chúng được sử dụng để tạo, trích xuất, suy luận — bất cứ nơi nào bạn đang sử dụng chính mô hình ngôn ngữ.
Có rất nhiều điều chúng ta có thể làm để cải thiện phần này:
- Prompt tốt hơn. Thêm các hướng dẫn, ràng buộc, schema rõ ràng. Sử dụng các cặp đầu vào-đầu ra few-shot để cho mô hình thấy bạn muốn gì.
- Thử một mô hình khác. Một số mô hình giỏi hơn trong việc tuân theo hướng dẫn, những mô hình khác lại xuất sắc về code hoặc khả năng ghi nhớ sự thật. Đừng cho rằng một mô hình là tốt nhất cho mọi thứ.
- Phân rã các nhiệm vụ khó thành các phần nhỏ hơn.
- Và fine-tune như một giải pháp cuối cùng. Fine-tuning rất mạnh mẽ nhưng tốn kém. Hãy để dành nó cho các hệ thống đã trưởng thành, nơi bạn cần những điểm phần trăm chất lượng cuối cùng đó và bạn đã cạn kiệt mọi thứ khác.
Giảm độ trễ
Đạt được chất lượng đầu ra nên là bước đầu tiên của bạn. Sau đó, hãy nói về việc giảm độ trễ.
- Đo lường thời gian
Bước đầu tiên là đo thời gian mỗi bước trong quy trình làm việc của bạn. Bạn có thể thấy một cái gì đó như, mất 7 giây để LLM tạo ra các thuật ngữ tìm kiếm. Tìm kiếm web mất 5 giây. Soạn thảo bài luận mất 11 giây, v.v.
Điều này cung cấp cho bạn một đường cơ sở để bạn biết mình nên tối ưu hóa cái gì.
- Song song hóa
Tiếp theo, chạy song song bất cứ thứ gì bạn có thể. Ví dụ có thể là lấy dữ liệu web, nhiều tìm kiếm, hoặc phân tích nhiều tài liệu. Đây thường là chiến thắng dễ dàng nhất.
- Chọn mô hình phù hợp
Sử dụng một LLM nhỏ hơn, nhanh hơn cho các nhiệm vụ đơn giản như tạo từ khóa, và dành mô hình hạng nặng cho việc tổng hợp và suy luận.
- Thử các nhà cung cấp nhanh hơn.
Thông lượng và tốc độ streaming token rất khác nhau. Một nhà cung cấp có hệ thống phục vụ được tối ưu hóa có thể cắt giảm vài giây mà không cần thay đổi prompt.
- Cuối cùng, cắt bớt ngữ cảnh.
Các prompt và ngữ cảnh ngắn hơn có nghĩa là giải mã nhanh hơn, vì vậy hãy cố gắng chỉ giữ lại những gì bước đó thực sự cần.
Giảm chi phí
Với chất lượng cao và độ trễ được kiểm soát, bạn đã sẵn sàng để xem xét chi phí. Để bắt đầu, bạn sẽ muốn đo lường chi phí của mỗi bước giống như với độ trễ.
Các hệ thống agent có một số nguồn chi phí:
Các lệnh gọi LLM: Điều này được xác định bởi token đầu vào và token đầu ra. Chúng thường được định giá riêng biệt (token đầu vào rẻ hơn và token đầu ra đắt hơn).
Các lệnh gọi API: Những thứ như tìm kiếm web, chuyển đổi PDF, tạo hình ảnh, chuyển giọng nói thành văn bản. Chúng thường có giá mỗi lần gọi hoặc mỗi đơn vị.
Cơ sở hạ tầng: Nếu bạn đang chạy các hệ thống truy xuất của riêng mình, cơ sở dữ liệu vector, hoặc máy tính để thực thi code.
Giả sử bạn đang xây dựng một agent nghiên cứu viết bài luận. Đây là chi phí cho một lần chạy:
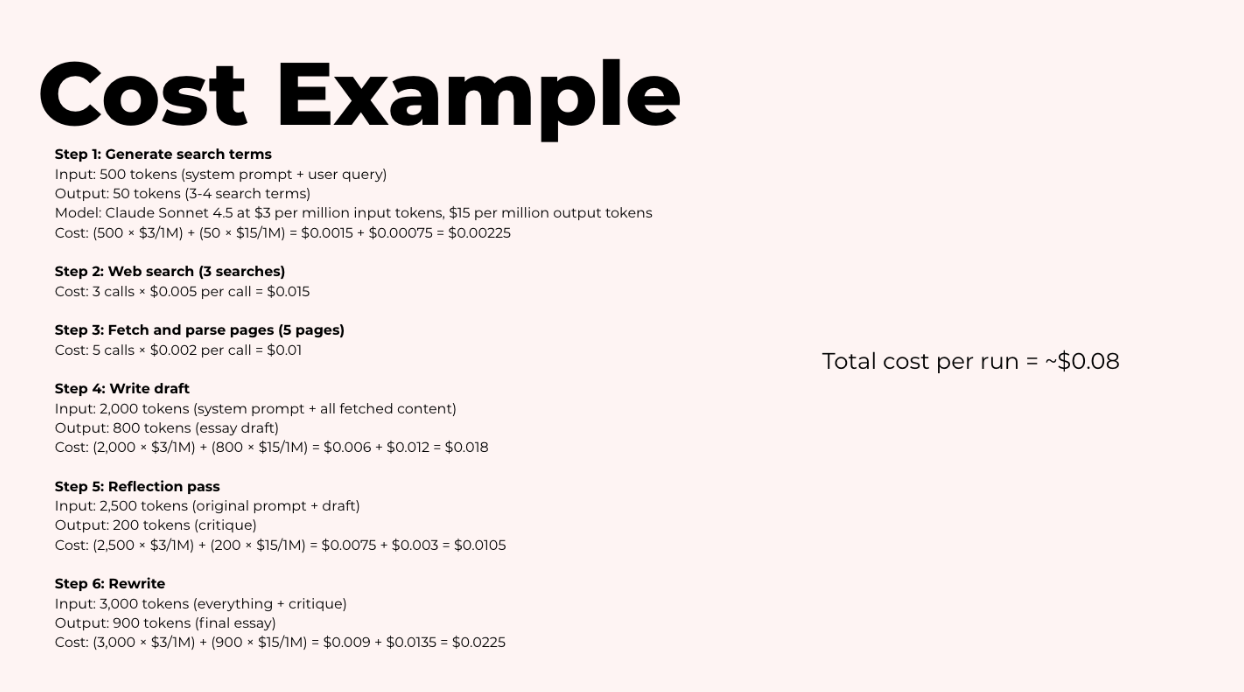
Nếu bạn chạy cái này 1.000 lần một ngày, đó là 80 đô la/ngày hoặc 2.400 đô la/tháng.
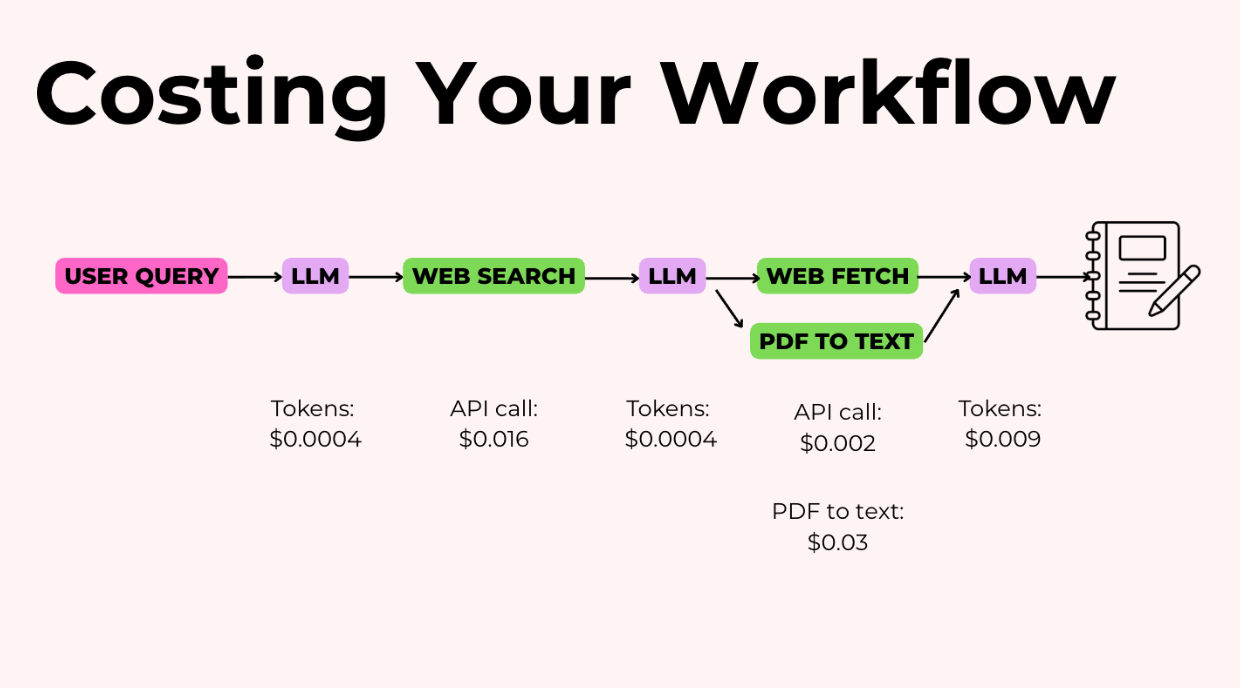
Khi bạn biết mỗi bước tốn bao nhiêu, đây là những gì bạn có thể làm để tối ưu hóa:
- Tấn công vào các khoản lớn trước. Nếu tìm kiếm web tốn 2 cent mỗi lần gọi và bạn gọi nó 10 lần mỗi lần chạy, đó là 20 cent ngay lập tức. Hãy cố gắng hết sức để giảm số lần gọi, lưu kết quả vào bộ nhớ đệm, hoặc gộp các truy vấn.
- Phân cấp các mô hình của bạn. Sử dụng các mô hình rẻ tiền cho các nhiệm vụ dễ dàng và các mô hình tiên tiến chỉ ở những nơi thực sự quan trọng.
- Lưu vào bộ nhớ đệm một cách tích cực. Các kết quả có tính xác định như phản hồi tìm kiếm, embedding, truy xuất chunk, hoặc các bản tóm tắt trung gian không nên được tính toán lại mỗi lần.
- Hạn chế đầu ra. Yêu cầu các kết quả có cấu trúc, ngắn gọn với các hướng dẫn như "Trả về JSON với các trường bắt buộc này." "Cho tôi tối đa 5 gạch đầu dòng." Ít token hơn, hóa đơn thấp hơn.
- Và xử lý theo lô (batch). Nếu bạn đang xử lý nhiều mục tương tự, hãy gộp các hoạt động lại khi có thể. Ví dụ, trên AWS, xử lý theo lô có chi phí bằng 50% so với theo yêu cầu.
Khả năng quan sát và giám sát
Vậy là bạn có một hệ thống với chất lượng, độ trễ và chi phí mà bạn hài lòng. Bây giờ chúng ta cần đảm bảo nó tiếp tục hoạt động như mong đợi khi mở rộng quy mô.
Đây là lúc khả năng quan sát và giám sát phát huy tác dụng. Khả năng quan sát bao gồm khả năng gỡ lỗi, giám sát chất lượng và theo dõi ảo giác. Về cơ bản, bất cứ điều gì giúp bạn theo dõi hành vi và hiệu suất của agent.
Phần khó khăn là khả năng quan sát cho các hệ thống AI về cơ bản khác với phần mềm truyền thống.
Với phần mềm truyền thống, bạn có thể theo dõi một đường thực thi rõ ràng. Hàm A gọi Hàm B, truy vấn cơ sở dữ liệu, trả về dữ liệu, hiển thị một trang. Những thứ như vậy.
Các hệ thống AI không hoạt động theo cách đó, vì nhiều lý do khác nhau:
- Chúng không xác định. Cùng một đầu vào có thể tạo ra các đầu ra khác nhau dựa trên phản hồi của mô hình. Bạn không thể chỉ phát lại một yêu cầu và mong đợi cùng một kết quả.
- Chúng có thực thi phân tán với các công cụ chạy song song, các agent sinh ra các agent con, v.v.
- Rất nhiều phụ thuộc bên ngoài với các điểm lỗi tiềm ẩn nằm ngoài tầm kiểm soát của bạn.
- Và nhiều hơn nữa!
Để quản lý tất cả những điều này, chúng ta cần hai loại khả năng hiển thị:
- Chỉ số "chi tiết" (zoom-in) giúp bạn gỡ lỗi các lần chạy đơn lẻ. Đây là dấu vết đầy đủ của bạn: prompt, lệnh gọi công cụ, sử dụng token, số lần thử lại và mọi điểm quyết định. Về cơ bản là mọi thứ cần thiết để tái tạo một lỗi và xem chính xác nó đã sai ở đâu.
- Chỉ số "tổng quan" (zoom-out) cho bạn biết toàn bộ hệ thống đang hoạt động như thế nào qua nhiều lần chạy. Điều này bao gồm các kiểm tra chất lượng tự động (thường với một LLM-làm-giám-khảo), tỷ lệ ảo giác, các biện pháp thành công/ROI, và các đường xu hướng cho thấy liệu các thay đổi đang giúp ích hay gây hại.
Bạn sẽ muốn ghi lại không chỉ những gì một agent đã làm, mà cả lý do tại sao nó làm vậy. Ví dụ, bạn có thể ghi lại những thứ như: "Agent đã chọn sử dụng tìm kiếm web thay vì RAG vì truy vấn chứa 'gần đây'" hoặc "Lượt suy ngẫm đã xác định 3 vấn đề: thiếu trích dẫn, ngày tháng mơ hồ, giọng điệu sai"
Khi bạn đang chạy hàng ngàn agent cùng một lúc, bạn không thể theo dõi thủ công từng dấu vết. Đây là lúc lấy mẫu chất lượng (quality sampling) phát huy tác dụng. Thay vì kiểm tra sâu từng lần thực thi, bạn xác định một tỷ lệ lấy mẫu — ví dụ, một tỷ lệ phần trăm nhất định của tổng số lần chạy — để được đánh giá về chất lượng và ảo giác. Hệ thống sau đó sử dụng tập hợp con các lần thực thi đó để tính toán điểm chất lượng tổng thể và điểm ảo giác cho các agent của bạn.
Điều này cho phép bạn ưu tiên các bản sửa lỗi và các lĩnh vực cần cải thiện.
Ngoài các chỉ số kỹ thuật, bạn cần hiểu hành vi của người dùng.
- Mọi người thực sự đang yêu cầu điều gì? Họ có đang sử dụng agent của bạn như dự định, hay họ đã tìm ra những cách giải quyết sáng tạo?
- Họ bị mắc kẹt ở đâu? Họ có diễn đạt lại và thử lại không? Đó là một tín hiệu cho thấy lần thử đầu tiên không hoạt động.
- Họ làm gì với đầu ra? Nếu họ ngay lập tức yêu cầu sửa đổi, chất lượng ban đầu không đủ tốt.
- Các phiên làm việc kéo dài bao lâu? Các phiên rất ngắn có thể có nghĩa là thành công nhanh chóng hoặc thất bại ngay lập tức. Các phiên rất dài có thể có nghĩa là agent có khả
Theo dõi trên X