AI tạo tác: Hệ thống đơn tác tử và đa tác tử

 Xây dựng các hệ thống agent khác nhau trong LangGraph | Ảnh: tác giả
Xây dựng các hệ thống agent khác nhau trong LangGraph | Ảnh: tác giả
Nếu bạn mới bắt đầu xây dựng các hệ thống tạo tác (agentic system) khác nhau, một trong những lĩnh vực thú vị là sự khác biệt giữa việc xây dựng một quy trình làm việc đơn tác tử và đa tác tử, hoặc có lẽ là sự khác biệt giữa việc làm việc với các hệ thống linh hoạt hơn và các hệ thống được kiểm soát.
Bài viết này sẽ giúp bạn hiểu AI tạo tác là gì và cách xây dựng các hệ thống tạo tác với LangGraph & LangSmith Studio.
Chúng ta sẽ xây dựng một nhà nghiên cứu (researcher) với hai kiến trúc khác nhau để có thể so sánh kết quả và hiểu kiến trúc nào hoạt động tốt hơn.
Bạn sẽ tìm thấy các tài nguyên chúng ta sẽ làm việc cùng tại đây. Việc chạy các hệ thống này hầu hết sẽ miễn phí, ngoại trừ một vài token của OpenAI.
Lưu ý, nếu bạn muốn có cái nhìn tổng quan về các framework mã nguồn mở khác nhau hiện có, hãy xem bài viết này.
Trường hợp sử dụng
Để xây dựng một thứ gì đó cụ thể, chúng ta sẽ tạo ra một agent nghiên cứu về công nghệ, có khả năng tìm ra những gì đang là xu hướng ngày hôm qua hoặc tuần trước, và sau đó xác định những gì đáng để đưa tin.
Làm việc với việc tóm tắt và thu thập nghiên cứu là một trong những lĩnh vực mà AI tạo tác thực sự có thể tỏa sáng.
Bài viết này sẽ sử dụng một API thu thập những gì mọi người đang nói và chia sẻ trong lĩnh vực công nghệ, và hệ thống tạo tác sẽ có nhiệm vụ quyết định điều gì là quan trọng dựa trên hồ sơ người dùng (user persona) của chúng ta, sau đó tóm tắt lại cho chúng ta.
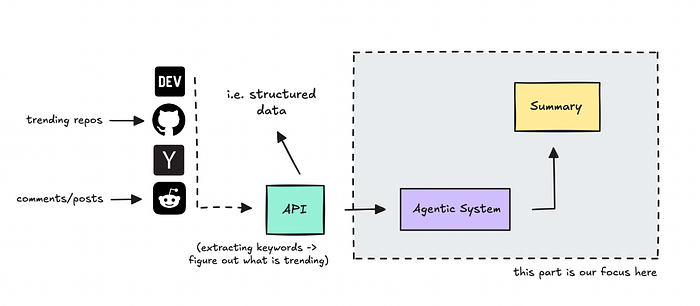 Nguồn dữ liệu cung cấp dữ liệu có cấu trúc để hệ thống tạo tác có thể làm việc
Nguồn dữ liệu cung cấp dữ liệu có cấu trúc để hệ thống tạo tác có thể làm việc
Agent sẽ không thêm bất kỳ trích dẫn nào vào văn bản, chúng ta đang xem xét mức độ bao quát của nó khi chỉ thiết lập một agent duy nhất so với khi thiết lập nhiều agent làm việc đồng bộ.
Do đó, trọng tâm không nằm ở nguồn dữ liệu mà ở phần tạo tác (agentic).
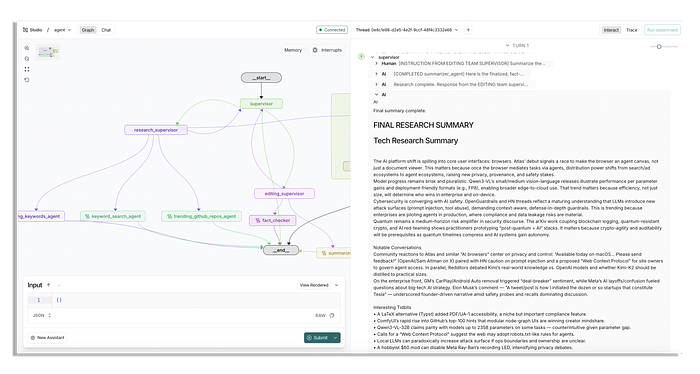 Ví dụ về hệ thống đa tác tử của chúng ta sẽ trông như thế nào trong LangSmith Studio, mất vài phút để hoàn thành | Ảnh: tác giả
Ví dụ về hệ thống đa tác tử của chúng ta sẽ trông như thế nào trong LangSmith Studio, mất vài phút để hoàn thành | Ảnh: tác giả
Chúng ta sẽ xây dựng hệ thống này trước tiên với một agent đơn giản có quyền truy cập vào các endpoint API khác nhau, và sau đó chúng ta sẽ xây dựng hệ thống để sử dụng nhiều nhóm (team) và các công cụ toàn diện hơn để thấy sự khác biệt về chất lượng.
Trước khi bắt đầu, tôi luôn có một phần ôn lại cho người mới. Nếu bạn đã rành về các hệ thống tạo tác, bạn có thể bỏ qua một vài phần đầu tiên.
AI tạo tác & LLMs
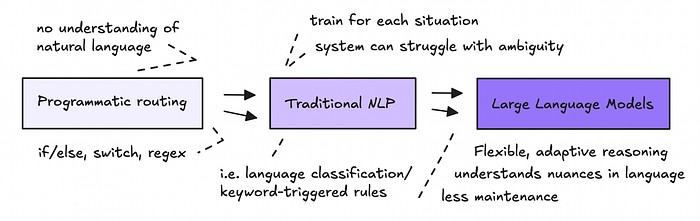
AI tạo tác là về việc lập trình bằng ngôn ngữ tự nhiên. Thay vì sử dụng mã lệnh cứng nhắc, rõ ràng, bạn đang chỉ thị cho các mô hình ngôn ngữ lớn (LLM) để định tuyến dữ liệu và thực hiện các hành động thông qua ngôn ngữ đơn giản để tự động hóa các tác vụ.
Việc sử dụng ngôn ngữ tự nhiên trong các quy trình làm việc không phải là mới, chúng ta đã sử dụng NLP trong nhiều năm để trích xuất và xử lý dữ liệu.
Điều mới mẻ là mức độ tự do mà chúng ta có thể trao cho các mô hình ngôn ngữ, cho phép chúng xử lý sự mơ hồ và đưa ra quyết định một cách linh hoạt.
Nhưng chỉ vì LLM có thể hiểu ngôn ngữ tinh tế không có nghĩa là chúng vốn đã xác thực được sự thật hay duy trì tính toàn vẹn của dữ liệu.
Tôi xem chúng chủ yếu như một lớp giao tiếp (ít nhất là ở thời điểm hiện tại) nằm trên các hệ thống có cấu trúc và các nguồn dữ liệu hiện có.
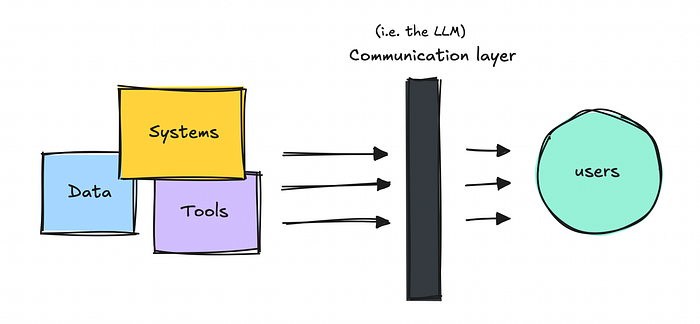
Tôi thường giải thích cho những người không chuyên về kỹ thuật như thế này: chúng hoạt động hơi giống chúng ta. Nếu chúng ta không có quyền truy cập vào dữ liệu sạch, có cấu trúc, chúng ta bắt đầu bịa chuyện. LLM cũng vậy.
Vì vậy, giống như chúng ta, chúng làm tốt nhất với những gì chúng có. Nếu chúng ta muốn đầu ra tốt hơn, chúng ta cần xây dựng các hệ thống cung cấp cho chúng dữ liệu hoặc hệ thống đáng tin cậy để làm việc.
Do đó, với các hệ thống Agentic, chúng ta tích hợp các cách để chúng tương tác với các nguồn dữ liệu, công cụ và hệ thống khác nhau.
Bây giờ, chỉ vì chúng ta có thể sử dụng các mô hình lớn hơn này ở nhiều nơi hơn, không có nghĩa là chúng ta luôn nên làm vậy. LLM tỏa sáng khi diễn giải ngôn ngữ tự nhiên tinh tế, hãy nghĩ đến dịch vụ khách hàng, nghiên cứu, hoặc sự hợp tác có con người trong vòng lặp (human-in-the-loop).
Nhưng đối với các tác vụ có cấu trúc (như trích xuất số và gửi chúng đi đâu đó), bạn có thể sử dụng các phương pháp và tự động hóa truyền thống.
LLM vốn không giỏi toán hơn một chiếc máy tính. Vì vậy, thay vì để LLM thực hiện các phép tính, bạn hãy cho LLM quyền truy cập vào một chiếc máy tính.
Vì vậy, bất cứ khi nào bạn có thể xây dựng các phần của một quy trình làm việc theo phương pháp lập trình, đó vẫn sẽ là lựa chọn tốt hơn.
Tuy nhiên, LLM rất giỏi trong việc thích ứng với đầu vào lộn xộn của thế giới thực và diễn giải các chỉ dẫn mơ hồ, vì vậy việc kết hợp cả hai có thể là một cách tuyệt vời để xây dựng hệ thống.
Nếu bạn còn rất mới với lĩnh vực này và vẫn còn bối rối, hãy xem qua một số bài viết khác của tôi giải thích chi tiết hơn. Có thể nó sẽ dễ hiểu hơn khi chúng ta bắt tay vào xây dựng sau này.
Các framework tạo tác và LangGraph
Tôi biết rất nhiều người nhảy thẳng vào CrewAI hoặc AutoGen cho agent đầu tiên của họ, nhưng chúng ta có rất nhiều lựa chọn. Trong bài viết này, tôi sẽ giới thiệu cho bạn LangGraph.
LangGraph là một framework dựa trên đồ thị (graph-based) được xây dựng trên nền tảng LangChain. Tôi cho rằng nó có tính kỹ thuật cao hơn và có thể phức tạp hơn so với các framework khác. Tuy nhiên, nó là lựa chọn ưa thích của nhiều nhà phát triển, đó là lý do tại sao việc xây dựng ít nhất một thứ gì đó với nó là điều đáng giá.
Tuy nhiên, LangGraph có rất nhiều lớp trừu tượng (abstractions), nơi bạn có thể muốn xây dựng lại một số phần chỉ để có thể kiểm soát và hiểu nó tốt hơn.
Tôi sẽ không đi sâu vào chi tiết về LangGraph ở đây, vì vậy tôi đã quyết định xây dựng một hướng dẫn nhanh cho những ai cần xem lại.
Nếu bạn muốn có cái nhìn tổng quan về các framework khác nhau hiện có, tôi đã viết một số bài về chủ đề này tại đây và đã thu hút hơn 100 nghìn lượt đọc.
Tôi nên lưu ý rằng ngày nay tôi thích không dùng framework nào cả khi xây dựng, nhưng tôi sao chép rất nhiều từ những gì tôi đã học được từ các framework khác nhau, vì vậy việc học cách làm việc với chúng vẫn rất đáng giá.
Đối với trường hợp sử dụng này, bạn sẽ có thể chạy quy trình làm việc mà không cần viết mã, nhưng nếu bạn ở đây để học, bạn cũng có thể muốn hiểu cách LangGraph hoạt động.
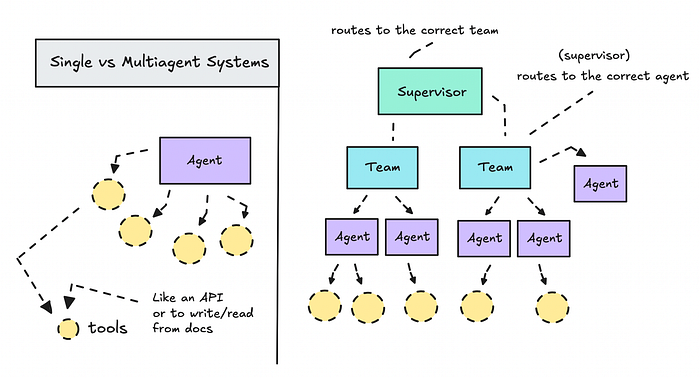
Hệ thống đơn tác tử và đa tác tử
Trước khi chúng ta đi sâu vào việc xây dựng, hãy cùng tìm hiểu sự khác biệt giữa hệ thống đơn tác tử và đa tác tử.
Nếu bạn xây dựng một hệ thống xoay quanh một LLM và cung cấp cho nó một loạt công cụ bạn muốn nó sử dụng, bạn đang làm việc với một quy trình làm việc đơn tác tử. Nó nhanh, và nếu bạn mới làm quen với AI tạo tác, có vẻ như mô hình chỉ cần tự mình tìm ra mọi thứ.
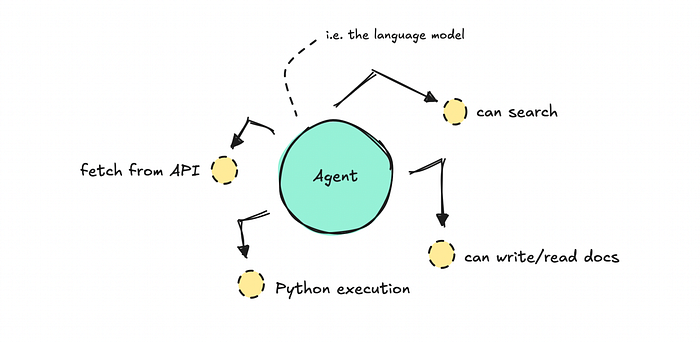
Nhưng vấn đề là các quy trình làm việc này chỉ là một dạng khác của thiết kế hệ thống.
Giống như bất kỳ dự án phần mềm nào, bạn cần lập kế hoạch quy trình, xác định các bước, cấu trúc logic và quyết định cách mỗi phần nên hoạt động.
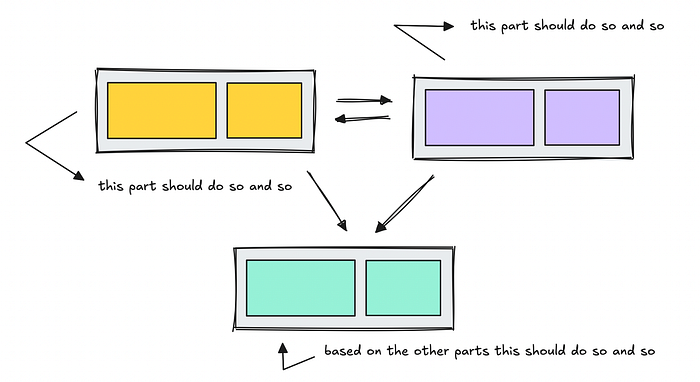
Đây là lúc các quy trình làm việc đa tác tử phát huy tác dụng.
Không phải tất cả chúng đều có cấu trúc phân cấp hoặc tuyến tính, một số mang tính hợp tác. Các quy trình làm việc hợp tác sau đó cũng sẽ thuộc vào phương pháp tiếp cận linh hoạt hơn mà tôi thấy khó làm việc hơn, ít nhất là ở thời điểm hiện tại với các khả năng hiện có.
Tuy nhiên, các quy trình làm việc hợp tác cũng chia nhỏ các chức năng khác nhau thành các module riêng của chúng.
Các quy trình làm việc hợp tác rất tuyệt để bắt đầu khi bạn chỉ đang thử nghiệm, nhưng chúng không phải lúc nào cũng cho bạn độ chính xác cần thiết cho các nhiệm vụ thực tế.
Đối với quy trình làm việc mà tôi sẽ xây dựng ở đây, tôi đã biết cách các API nên được sử dụng, vì vậy công việc của tôi là hướng dẫn hệ thống sử dụng chúng đúng cách.
Chúng ta sẽ so sánh một thiết lập đơn tác tử với một hệ thống đa tác tử phân cấp, trong đó một agent trưởng phân công nhiệm vụ cho một nhóm nhỏ để bạn có thể thấy chúng hoạt động như thế nào trong thực tế.
Xây dựng một agent đơn
Để xây dựng một agent đơn, chúng ta làm việc với một LLM và một system prompt cho nó, sau đó chúng ta cấp cho nó quyền truy cập vào một số công cụ.
Việc quyết định công cụ nào sẽ sử dụng và khi nào, dựa trên câu hỏi của người dùng, là tùy thuộc vào agent.
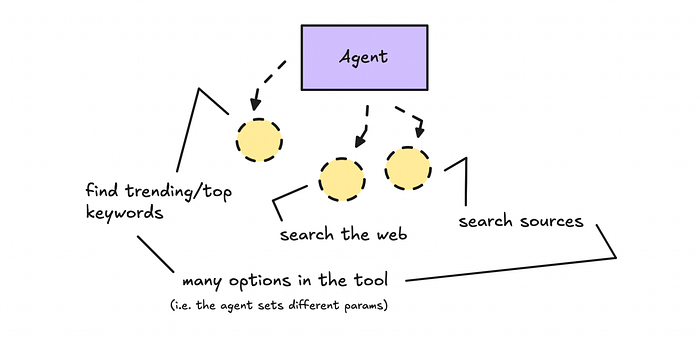
Thách thức với một agent đơn là khả năng kiểm soát.
Dù system prompt có chi tiết đến đâu, mô hình có thể không tuân theo yêu cầu của chúng ta (điều này cũng có thể xảy ra trong các môi trường được kiểm soát hơn). Nếu chúng ta cung cấp cho nó quá nhiều công cụ hoặc tùy chọn, rất có thể nó sẽ không sử dụng tất cả hoặc thậm chí không sử dụng đúng công cụ.
Chúng ta chỉ có thể thiết lập một mức độ nhất định trong các chỉ dẫn để nó hành động theo ý muốn.
Để minh họa điều này, chúng ta sẽ xây dựng agent tin tức công nghệ có quyền truy cập vào một số endpoint API với dữ liệu tùy chỉnh và nhiều tùy chọn làm tham số trong các công cụ.
Việc quyết định sử dụng bao nhiêu công cụ và cách thiết lập bản tóm tắt cuối cùng là tùy thuộc vào agent.
Hãy nhớ, tôi xây dựng các quy trình làm việc này bằng LangGraph. Tôi sẽ không đi sâu vào LangGraph ở đây, vì vậy nếu bạn muốn học những điều cơ bản để có thể tinh chỉnh mã, hãy đến đây (hướng dẫn này từ tháng 4 năm 2025).
Bạn có thể tìm thấy quy trình làm việc đơn tác tử tại đây. Để chạy nó, bạn cần có tài khoản đăng nhập LangSmith, nơi bạn có quyền truy cập vào LangSmith Studio, và đã cài đặt python 3.
Khi bạn đã có tài khoản, bạn có thể clone quy trình làm việc đơn tác tử về máy tính của mình.
Nó sẽ có cấu trúc như sau.
single-agent-workflow/
├─ my_agent/
│ ├─ agent.py
│ ├─ requirements.txt
│ ├─ utils/
│ ├─ nodes.py
│ ├─ state.py
│ └─ tools.py
├─ README.md
├─ langgraph.json
Tạo một tệp .env và thêm khóa API của Google. Chúng ta sẽ sử dụng Gemini cho agent đơn này.
GOOGLE_API_KEY=KEY_HERE
Sau đó, thiết lập một môi trường ảo.
python3.11 -m venv venv_py311
source venv_py311/bin/activate
Cài đặt LangGraph cli.
pip install -U "langgraph-cli[inmem]"
Bạn sẽ tìm thấy các yêu cầu trong thư mục my_agent và bạn cũng sẽ cài đặt chúng.
pip install -r my_agent/requirements.txt
Sau khi chúng đã được tải xuống, bạn có thể mở quy trình làm việc đơn tác tử trong LangSmith studio.
langgraph dev
Thao tác này sẽ tự động mở LangSmith Studio (trước đây là LangGraph Studio).
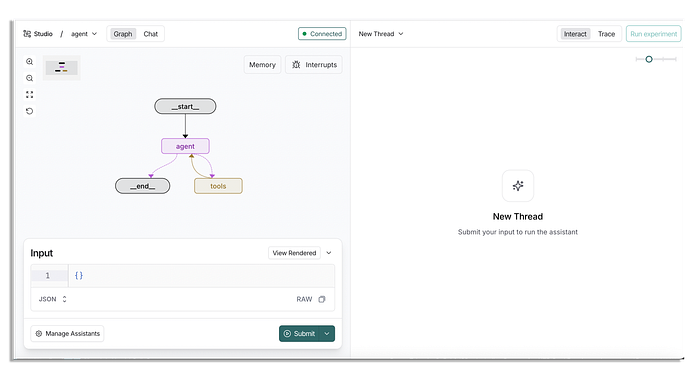
Điều quan trọng là bạn cũng phải thiết lập một assistant ở đây, vì mặc định sẽ được đặt thành Anthropic và chúng ta đang sử dụng Gemini cho agent này.
Để quản lý các assistant, hãy nhấp vào nút ở góc dưới cùng bên trái.
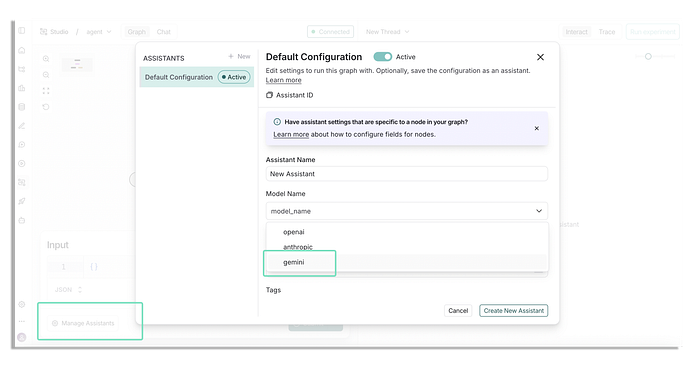 Hãy chắc chắn bạn tạo một assistant mới với 'gemini' và nhấp vào 'create new assistant' | Ảnh: tác giả
Hãy chắc chắn bạn tạo một assistant mới với 'gemini' và nhấp vào 'create new assistant' | Ảnh: tác giả
Bạn sẽ thấy một cửa sổ modal như trên. Đặt mô hình thành 'gemini' và sau đó nhấp vào 'Create New Assistant'.
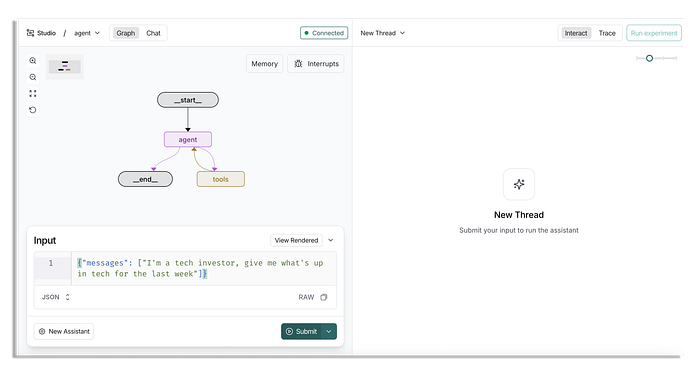
Khi bạn quay lại màn hình chính, bạn có thể đặt một tin nhắn bắt đầu.
Đối với tin nhắn này, bạn có thể cho nó biết bạn muốn gì, chẳng hạn như bạn làm việc với lĩnh vực nào và bạn muốn thông tin hàng ngày, hàng tuần hay hàng tháng (xem ví dụ bên dưới).
{"messages": ["I'm a tech investor, give me what's up in tech for the last week"]}
Nó sẽ trông như thế này trong LangSmith Studio.
Khi bạn nhấp vào submit, kết quả sẽ rất nhanh, vì chúng ta đang làm việc với một agent đơn.
Nó quyết định trước tiên kiểm tra một vài từ khóa xu hướng trong 3 danh mục khác nhau và sau đó kiểm tra xem mọi người đang nói gì về một vài từ khóa xu hướng đó.
Nếu bạn muốn hiểu cách các công cụ này được tạo ra, hãy chắc chắn kiểm tra bên trong mã nguồn nhưng nó chỉ đơn giản là sử dụng một API.
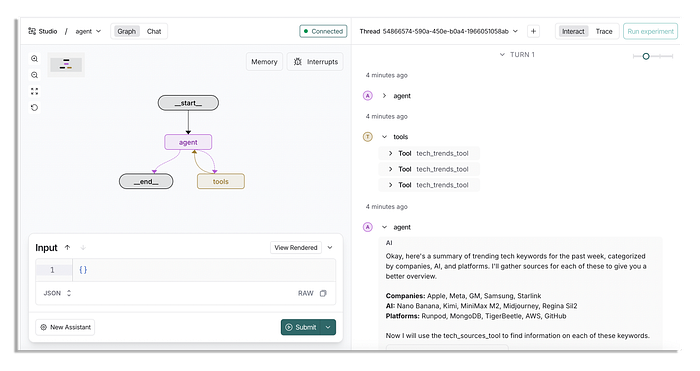
Kết quả cuối cùng trông như thế này (mặc dù nó phụ thuộc vào thời điểm bạn chạy, thông tin rõ ràng sẽ khác nhau mỗi ngày).
Here's a summary of the trending tech topics from the past week:
Companies:
Apple: Apple is facing scrutiny over its App Store practices, including a UK monopoly case and concerns about attention to detail. There are also reports of reduced iPhone Air production and its potential move to include ads in the Maps app.
Meta: Meta is undergoing layoffs in its AI division, which has generated negative sentiment. There is also discussion around a mod that disables the recording light on Meta's Ray-Ban glasses, raising privacy concerns.
GM: GM's decision to ditch Apple CarPlay and Android Auto in future vehicles has sparked controversy and negative reactions from users.
Samsung: Samsung is planning to introduce ads on its smart fridges, drawing criticism. There's also news about the upcoming Galaxy XR event and a new chief design officer.
[...]
Nếu bạn muốn đọc toàn bộ mà không cần tự mình khởi động agent, hãy xem nó tại đây. Kết quả khá ổn, nhưng như bạn có thể thấy, nó không đào sâu cho lắm.
Tất nhiên, chúng ta có thể thăm dò và tiếp tục hỏi nó các câu hỏi nhưng như bạn có thể tưởng tượng, nếu chúng ta cần một thứ gì đó phức tạp hơn, nó sẽ bắt đầu đi đường tắt trong quy trình làm việc.
Điều quan trọng là, một hệ thống agent sẽ không tự động suy nghĩ theo cách chúng ta mong đợi, chúng ta phải thực sự điều phối nó để làm những gì chúng ta muốn.
Điều này ổn miễn là chúng ta có con người trong vòng lặp (human-in-the-loop), cho việc hỏi đáp, những thứ tương tự.
Đối với trường hợp này, nếu một người hỏi một điều và agent lấy thông tin đó, nó sẽ hoạt động rất tốt.
Tuy nhiên, để nghiên cứu sâu, chúng ta cần xây dựng một hệ thống phức tạp hơn một chút, chúng ta có thể làm điều này với một hệ thống giống như quy trình làm việc (mỗi phần làm một việc), hoặc chúng ta có thể thử xây dựng một hệ thống phân cấp nơi một agent (hoặc nhóm) chịu trách nhiệm cho một việc.
Thử nghiệm quy trình làm việc đa tác tử
Xây dựng hệ thống đa tác tử khó hơn nhiều so với việc xây dựng một agent đơn với quyền truy cập vào một số công cụ.
Để làm điều này, bạn cần suy nghĩ cẩn thận về kiến trúc trước và cách dữ liệu nên luân chuyển giữa các agent.
Quy trình làm việc đa tác tử này mà tôi sẽ thiết lập ở đây sử dụng hai nhóm khác nhau (một nhóm nghiên cứu và một nhóm biên tập) với nhiều agent dưới mỗi nhóm.
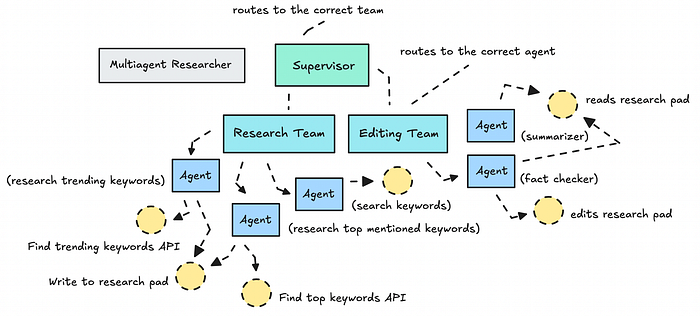 Ví dụ về kiến trúc của các nhóm/agent trong hệ thống đa tác tử của chúng ta | Ảnh: tác giả
Ví dụ về kiến trúc của các nhóm/agent trong hệ thống đa tác tử của chúng ta | Ảnh: tác giả
Mỗi agent có quyền truy cập vào một bộ công cụ cụ thể (không quá nhiều) và các chỉ dẫn rõ ràng.
Phạm vi giới hạn này cho mỗi agent rất tuyệt vời khi làm việc với các LLM cấp thấp hơn (ví dụ: Gemini Flash 2.0), mặc dù tôi luôn thích sử dụng một LLM tiên tiến hơn để tóm tắt (trong trường hợp này, chúng ta đang sử dụng GPT-5 làm agent tóm tắt).
Chúng ta đang giới thiệu một số công cụ mới, như một sổ ghi chép nghiên cứu (research pad) hoạt động như một không gian chia sẻ (một nhóm viết những phát hiện của họ, nhóm kia đọc từ đó). LLM cuối cùng sẽ đọc mọi thứ đã được nghiên cứu và biên tập để tạo ra một bản tóm tắt.
Một giải pháp thay thế cho việc sử dụng sổ ghi chép nghiên cứu là lưu trữ dữ liệu trong một vùng nháp (scratchpad) trong trạng thái (state), cách ly bộ nhớ ngắn hạn cho mỗi nhóm hoặc agent. Nhưng điều đó cũng có nghĩa là phải suy nghĩ cẩn thận về những gì bộ nhớ của mỗi agent nên bao gồm.
Tôi cũng quyết định xây dựng các công cụ một cách chi tiết hơn để cung cấp dữ liệu phong phú hơn ngay từ đầu, để các agent không phải tìm nguồn cho từng từ khóa một cách riêng lẻ. Ở đây tôi đang sử dụng logic lập trình thông thường vì tôi có thể.
Một điều quan trọng cần nhớ: nếu bạn có thể sử dụng logic lập trình thông thường, hãy làm vậy.
Quy trình làm việc đã được thiết lập sẵn cho bạn tại đây. Trước khi tải nó, hãy chắc chắn thêm cả khóa API OpenAI và Google của bạn vào tệp .env.
GOOGLE_API_KEY=KEY_HERE
OPENAI_API_KEY=KEY_HERE
ANTHROPIC_API_KEY=KEY_HERE
Bạn chỉ cần đặt khóa Anthropic nếu bạn sẽ thử nghiệm thay đổi các agent (nhưng nó có thể báo lỗi nếu bạn không đặt, trong trường hợp đó hãy chắc chắn thiết lập một assistant chỉ với Gemini).
Bạn sẽ cần làm tương tự như với quy trình làm việc đơn tác tử từ đây, thiết lập môi trường, cài đặt các yêu cầu và mở quy trình làm việc.
langgraph dev
Khi bạn đã mở nó lên, bạn sẽ thấy rằng nó trông phát triển hơn nhiều so với agent đơn của chúng ta.
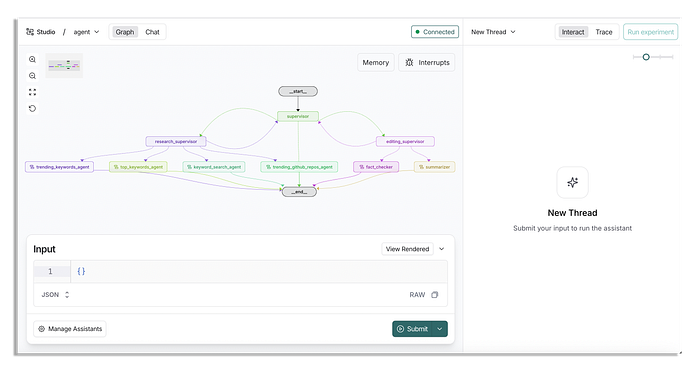
Trong quy trình làm việc này, các tuyến đường (edges) được thiết lập động thay vì thủ công như chúng ta đã làm với agent đơn. Nó sẽ trông phức tạp hơn nếu bạn xem qua mã nguồn.
Để chạy nó, bạn cần gửi một tin nhắn như lần trước.
Tôi đã quyết định đưa ra một prompt chi tiết hơn một chút ở đây, điều này hơi gian lận, bạn có thể thử một cái gì đó đơn giản hơn.
{"messages": ["{"messages": ["I'm an investor and I'm interested in getting an update for what has happened within the week in tech, and what people are talking about (this means categories like companies, people, websites and subjects are interesting). Please also track these specific keywords: AI, Google, Microsoft, and Large Language Models"]}"]}
Tốt hơn là bạn nên đặt lại những gì bạn đã đặt trước đó để có cái để so sánh, nhưng tùy bạn.
Khi nó bắt đầu, sẽ mất khá nhiều thời gian, vì vậy bạn có thể đi đâu đó rồi quay lại sau vài phút.
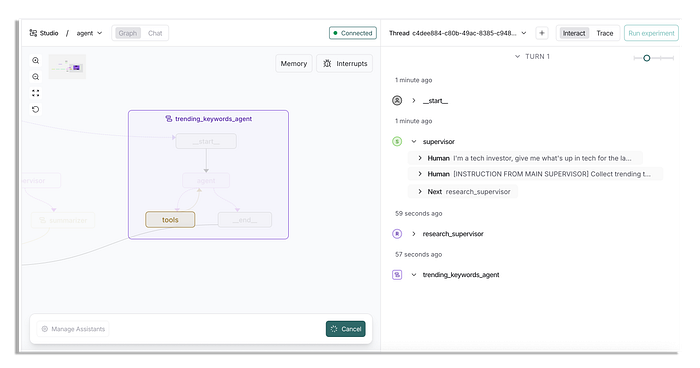
Các công cụ mà agent tìm từ khóa xu hướng có quyền truy cập phức tạp hơn so với agent đơn, vì vậy chúng mất nhiều thời gian hơn để trả về dữ liệu.
Nói chung, các hệ thống này cần thời gian để thu thập và xử lý thông tin và đó là điều chúng ta cần phải quen.
Bạn sẽ có thể xem các ghi chú mà nó thu thập được trong một thư mục có tên 'notes' ở thư mục gốc sau này. Bạn sẽ tìm thấy một ví dụ tại đây.
Bản tóm tắt cuối cùng sẽ trông giống như thế này:
FINAL RESEARCH SUMMARY
Tech Research Summary
Weekly Tech Investor Brief (week ending Oct 28, 2025)
Key Happenings
Oct 27: ICE signed a $5.7M contract for AI-powered social media surveillance (Reddit: r/technology)
Oct 27: “Windows 10 deadline boosts Mac sales” thread trended, highlighting OS/device churn (Hacker News)
Oct 26: Microsoft 365 Copilot arbitrary data exfiltration via Mermaid diagrams disclosed (Hacker News)
Oct 26: “It’s insulting to read AI-generated blog posts” topped HN, reflecting AI content fatigue (Hacker News)
[...]
Why It Matters
AI demand is moving from hype to operational scrutiny. Government adoption (e.g., ICE’s Oct 27 contract) signals durable budgets for AI monitoring and analytics, but also heightens regulatory and civil liberties overhang—an opening for compliant AI, privacy-tech, and auditing vendors. Enterprise posts on Microsoft 365 Copilot exfiltration and Teams attendance monitoring underscore a near-term buyer focus on security, governance, and employee trust, not just raw AI features.
Platform competition intensified. Google’s Oct 23 Earth AI updates and Google AI Studio “vibe coding” push indicate a bid to reduce time-to-production for AI apps, a likely driver of cloud/TPSU demand and developer lock-in. Meanwhile, community gravitation to open and self-hosted stacks (ComfyUI momentum; S3-compatible storage chatter) reflects a cost-control and control-residency theme—relevant for hybrid vendors and open-core plays.
Consumer backlash is shaping product roadmaps. GM’s removal of CarPlay/Android Auto is trending because it challenges perceived table-stakes features, risking brand equity and sales. Apple’s reported ads in Maps and YouTube’s deepfake measures reflect a broader tension between monetization, safety, and user experience—areas where differentiated policy and design can become competitive moats.
[...]
Bạn có thể đọc toàn bộ tại đây nếu bạn muốn xem mà không cần tự chạy.
Tin tức rõ ràng sẽ thay đổi tùy thuộc vào thời điểm bạn chạy quy trình làm việc. Tôi đã chạy nó vào ngày 28 tháng 10 nên báo cáo ví dụ sẽ dành cho ngày này.
Về kết quả, tôi sẽ để bạn tự quyết định sự khác biệt giữa việc sử dụng một hệ thống phức tạp hơn so với một hệ thống đơn giản, và cách nó cho chúng ta nhiều quyền kiểm soát hơn đối với quy trình.
Một vài ghi chú cuối cùng
Tôi đang làm việc với một nguồn dữ liệu tốt ở đây. Nếu không có nó, bạn sẽ cần thêm rất nhiều xử lý lỗi, điều này sẽ làm mọi thứ chậm lại hơn nữa.
Dữ liệu sạch và có cấu trúc là chìa khóa. Nếu không có nó, LLM sẽ không hoạt động tốt nhất. Ngay cả với dữ liệu vững chắc, nó cũng không hoàn hảo. Bạn vẫn cần phải làm việc trên các agent để đảm bảo chúng làm những gì chúng được cho là phải làm.
Có lẽ bạn đã nhận thấy hệ thống hoạt động nhưng nó vẫn chưa hoàn thiện. Vẫn còn một số điều cần cải thiện: phân tích cú pháp truy vấn của người dùng thành một định dạng có cấu trúc hơn và thêm các rào cản (guardrails) để các agent luôn sử dụng công cụ của chúng. Chúng ta cũng có thể muốn đảm bảo hệ thống sẽ tóm tắt hiệu quả hơn để giữ cho tài liệu nghiên cứu ngắn gọn.
Chúng ta cần giới thiệu xử lý lỗi tốt hơn, và có lẽ là bộ nhớ "dài hạn" để hiểu rõ hơn những gì người dùng thực sự cần. Trạng thái (bộ nhớ ngắn hạn) đặc biệt quan trọng nếu bạn muốn tối ưu hóa hiệu suất và chi phí.
Hiện tại, chúng ta chỉ đang đẩy mọi tin nhắn vào trạng thái và cho tất cả các agent quyền truy cập vào nó, điều này không lý tưởng. Chúng ta thực sự muốn tách biệt trạng thái giữa các nhóm. Trong trường hợp này, đó là điều tôi chưa làm, nhưng bạn có thể thử bằng cách giới thiệu một vùng nháp (scratchpad) trong lược đồ trạng thái để cách ly những gì mỗi nhóm biết.
Dù sao đi nữa, tôi hy vọng đó là một trải nghiệm thú vị để hiểu được kết quả chúng ta có thể nhận được bằng cách xây dựng các hệ thống tạo tác khác nhau. Nếu bạn thích nó, hãy chắc chắn thích, bình luận hoặc chia sẻ nó.
Theo dõi trên X